人工智慧、神經網路和手寫辨識技術
人工智慧技術改變了我們對人類書寫行為的看法,更將數位手寫技術推向新高峰
人工智慧技術的重要性
「人工智慧」的英文縮寫是 AI, 代表一門電子計算機科學,目的是建立聰明的電腦,能夠複製和強化人腦的特定能力,例如閱讀、瞭解或分析。
MyScript 的人工智慧
我們的核心軟體產品採用了專屬人工智慧技術。 我們用人工智慧解讀超過 70 種語言的手寫內容、分析手寫筆記的結構、瞭解數學方程式,甚至能辨識和轉換音符。
我們的技術歷經 20 多年研發。 為了打造全球最精確的手寫辨識引擎,我們一直在研究語言型態的細節:單字如何構成句子、字元如何構成單字、發音記號怎麼在特定母音的上面還是下面,依此類推。
MyScript 有好幾個研究小組通力合作,因此能打造最好的系統並加以改良,進而瞭解多種手寫內容。
文字手寫研究
我們的文字手寫研究小組利用機器學習技術,解決序列到序列(簡稱 seq2seq)的轉換問題,例如把手寫文字拆分成各個字元。
這些技術必須根據不同語言的字和語言習慣調整,才能辨識由右至左的語言(例如阿拉伯文或希伯來文)、印度文的重音母音、中文、韓文或直書的日文平假名、平假名或漢字。
2D 手寫研究
這個小組根據二維空間剖析程式或文法建立數學模型, 能解決 seq2seq 法無法處理的問題,例如辨識數學算式、音符或圖表。 他們採用圖形導向辨識技術,主要難題在於即時處理資料。
自然語言處理研究
我們的自然語言處理(NLP)小組負責開發演算法,讓演算法跟人一樣,能自然而然的瞭解語言。 這個小組利用公開的文件和文章,建立高達幾億字的語料庫。 有了這些語料庫,他們就能建立語言字彙,並且精心打造語言模型,以便預測句子中的下一個字,並且設計能辨識和糾正錯字的系統。
資料收集
如果沒有各國使用者自願提供匿名處理過的資料樣本,我們的工作可能就無以為繼。 我們處理這些「訓練樣本」(人工智慧研究術語)時,一律嚴守最高的隱私權和安全標準。這些樣本也是公司的一大資產,能幫我們改良和加強公司的技術水準。

手寫辨識:難題
手寫辨識的技術難度非常高,因為每個人寫字的風格南轅北轍。 書寫者的年齡、慣用手、國別,甚至在什麼樣的材質上寫字,都對書寫結果影響甚鉅,而且我們還沒把不同語言和字母的影響考慮進去。
為了讓您瞭解困難在哪裡,您可以想一下:好的手寫辨識軟體應該要能從 30,000 個表意文字中辨識出一個正確的中文字, 也必須能辨識和解讀雙向書寫文字,這樣才能在書寫者使用由右至左的語言時繼續發揮功能(例如阿拉伯文或希伯來文),包括手寫內容中夾雜幾個由左至右書寫的外文。
草寫字跡讓軟體更難分隔和辨識個別字元,後來加上的筆畫(例如發音記號)更容易搞混。 這類筆記的版面經常毫無結構可言,因此自動化分析內容的技術困難很多。如果還加入其他類型的內容(例如數學算式和圖表),也會有相同難題。
時間也是一個因素:手寫辨識軟體必須即時提供結果,在使用者書寫的同時解讀輸入內容。 如果使用者在書寫期間修改內容,例如以劃掉的方式刪除文字、插入空格或移動段落,辨識引擎也必須能夠跟上。
除此之外,手寫辨識技術必須能分析輸入字元和手寫線條,讓使用者從網頁或其他 App 匯入已經輸入的文字,然後視需要手寫註解。 一個好的辨識引擎必須能夠精確解讀這麼複雜的互動過程、區別編輯手勢、所加入的發音記號,或者所寫的新字。
投資神經網路技術
20 多年前,全球的手寫辨識研究界把重心放在隱藏式馬可夫模型(Hidden Markov Models,簡稱 HMM)和支援向量機(Support Vector Machines,簡稱 SVM)上,但是 MyScript 卻另闢蹊徑。
我們的重心反而放在神經網路上。
神經網路是一種機器學習技術,模擬人腦的學習過程。 神經網路採用威力強大的演算法,能在巨量資料集中找出模式,因此可針對我們研究的資料(例如手寫內容),提出更準確的歸納推理結果。
神經網路根植於數學模型。這些模型在「訓練」過後,能夠根據預先設定的變數(也稱「維度」)找出模式。 演算法經過細心的程式設計,能夠根據這些維度反覆分割和排列資料,並且不斷分類和重新分類,直到清楚的模式出現為止。
這樣一來,神經網路就能執行人類無法達成的工作。 這種技術能以高速篩選巨量資料,並且找出其他方式注意不到的模式。 我們認為神經網路技術能夠訓練出全球最精確也最先進的手寫辨識引擎。
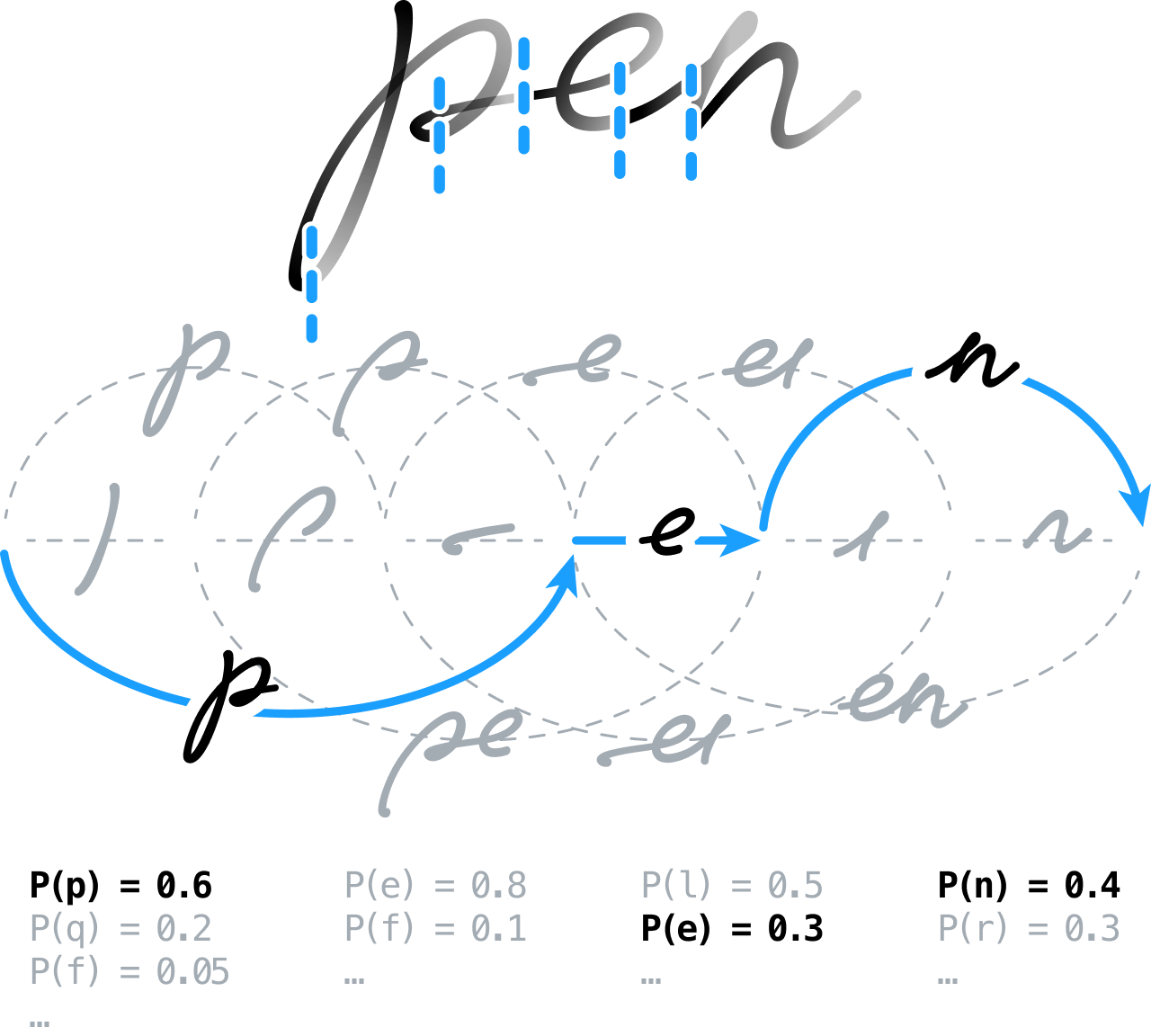
利用神經網路辨識手寫內容
我們的想法一開始就是預先處理手寫內容,以便做好分析準備,執行擷取線條、將筆跡標準化,以及修正偏斜筆畫等工作。 接下來,我們會過度切割訊號,讓辨識引擎以後再決定字元與字元以及字與字之間的界線位置。
這代表為了製作切割圖(segmentation graph),必須將所有可能的切割方式建立模型,也就是把連續的分割結果,組合成假設的字元,然後透過前饋神經網路(feedforward neural network)將這些假設予以分類。 我們採用依全球鑑別式訓練法設計的特殊做法。 現在這種技巧常用在連續性時序分類(Connectionist Temporal Classification,縮寫 CTC)架構中,專門訓練序列到序列神經系統。
我們也建置並採用最先進的統計語言模型,結合詞彙、文法和語意資訊,能用來澄清和解決不同候選字元之間剩下的模糊地帶。

針對二維語言訓練人工智慧
由於我們的神經網路大獲成功,因此能針對印刷和草寫字體打造全球最強的手寫辨識引擎。 然而,某些語言更為複雜,所以我們接著要討論下一個難題。
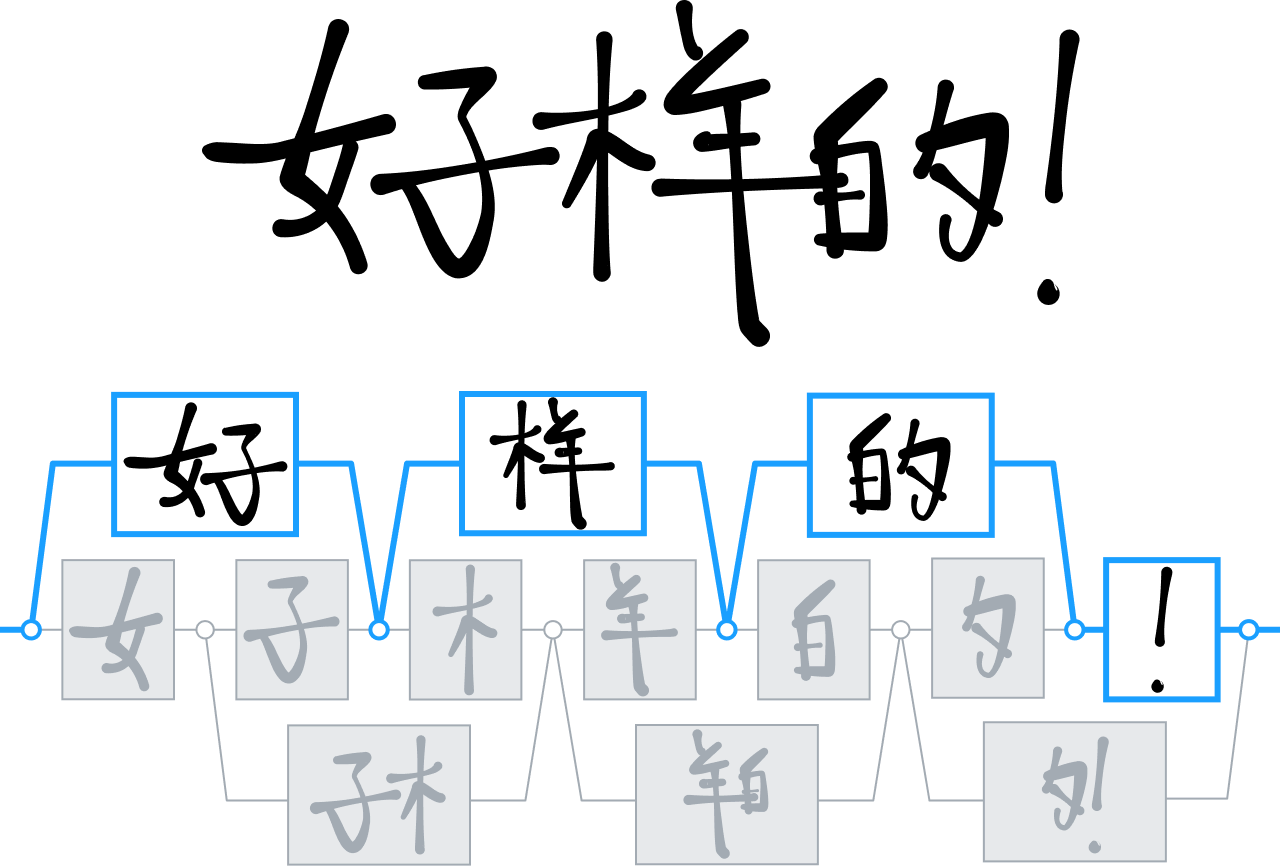
辨識中文
多年來,MyScript 為了分析和解讀二維語言(尤其是中文的表意文字),開發了多種技術。
業界大部分的競爭對手在分辨和解讀中文字時,都採用決策樹技術,但是我們卻加碼投資神經網路,訓練自家程式引擎辨識超過 30,000 個表意文字。
這是首次有研究團隊成功訓練出這麼多文字,全都得歸功於浩大的資料蒐集工程,組成有史以來最大的中文手寫文字資料集。
我們利用這些資料開發出全新的神經網路架構,能夠專門分析中文字結構,並且整合專門的叢集技術,以便加快處理速度。 因為有這些創新,我們才能針對非常難以鍵盤輸入文字,或者這麼做會欠缺彈性的市場,推出全新一代的手寫辨識產品, 也讓我們針對其他語言(例如日文、印度文和韓文),加入相同水準的支援功能。
數學辨識
我們用神經網路成功分析和辨識全球多種語言後,發現了嶄新目標:辨識數學算式。
一般語言有字元和單字的結構型序列特徵,二維(或視覺)語言則通常有樹狀或圖形結構,各個節點之間有空間關係。 我們的數學辨識系統跟文字一樣,基礎原則都是必須同時在同一層上處理分割、辨識、文法分析和語意分析工作,這樣才能產生最好的辨識候選字。
系統會根據專屬的特殊文法規則,分析數學方程式內所有元素的空間關係,再利用這種分析結果決定分割方式。 文法本身包含整組規則,描述如何剖析方程式。每項規則都和特定的空間關係有牽連。 舉例來說,「分數」規則決定了分子、分數橫線、分母之間的垂直關係定義。
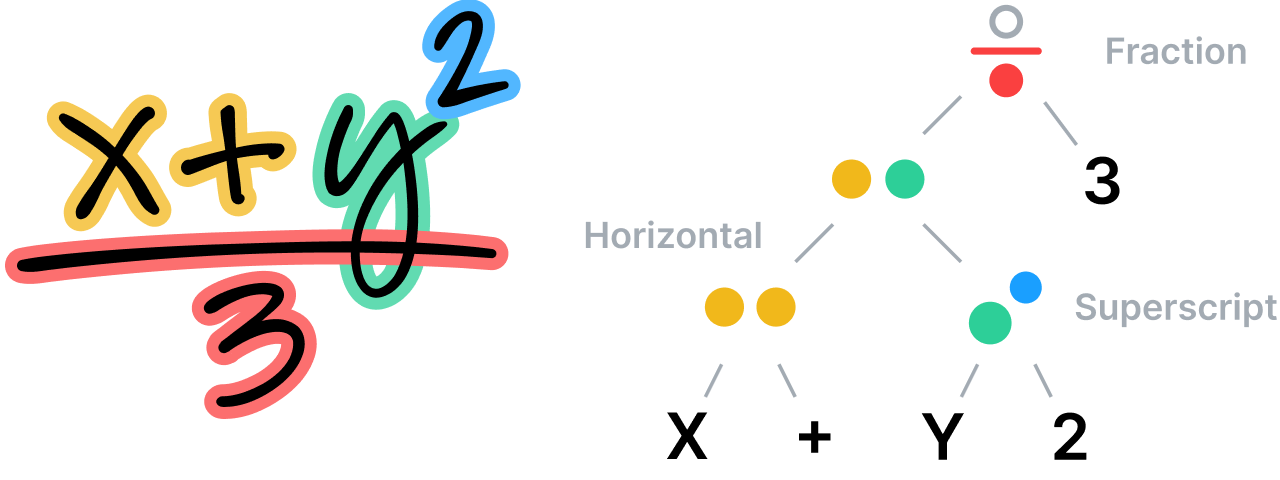
認識無結構筆記
由於我們的產品能馬上正確辨識數學算式,所以開啟了手寫筆記排版和內容的其他可能。
如果辨識引擎能正確解讀數學方程式中各要素的空間關係,是否也能正確辨識各種非文字內容呢? 如果可以,就能解決無結構筆記帶來的問題,運用我們的技術正確辨識內容,甚至能美化特定要素,例如手繪圖表。
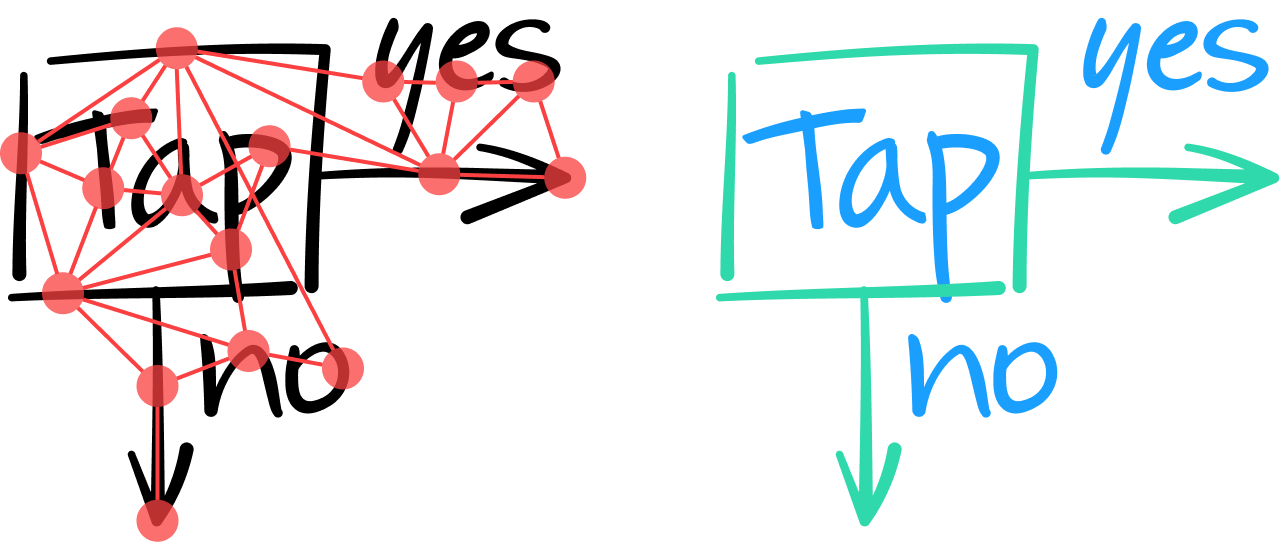
我們認為圖像神經網路(簡稱 GNN)架構非常適合這種工作。 基本概念是將整份文件轉換成圖像模型,線條以節點代表,並以相鄰線條的邊緣連接在一起。
以這種方式分析筆記內容時, 必須把所有線條分成文字或非文字。 為了做到這一點,必須分析每個線條本身的特徵,並在必要時考量線條鄰近邊緣和節點提供的脈絡資訊。
GNN 的其中一層會將多個相鄰節點的特徵結合,產生數值向量,代表更高階層的特徵。 和卷積神經網路一樣,多個層可以堆疊起來,找出更多整體特徵,因此在判斷某個線條是否包含文字筆畫時,就能根據更多資訊做出決策。 舉例來說,下圖最左邊的兩條垂直線看起來很像,但是在整合相鄰線條的脈絡資訊後,GNN 才能在輸出層判定,最左邊的線條其實屬於幾何正方形,旁邊的直線則屬於「T」這個字元。
深度學習和編解碼模型
提供兩套最佳文字和數學辨識系統不一定就足夠。對於從事科學工作或科學領域的學生而言更是如此。 這類使用者在連續寫字時,通常必須夾雜數學內容(也就是不在內頁的獨立空白處書寫)。他們會希望辨識引擎能正確解讀這兩種內容。
困難之處就在於所設計的系統,必須能夠辨識和數學算式混在一起的字元和單字,也就是分析自然無維度語言(文字)和二維語言(數學)。
在深度學習浪潮的席捲之下,全新的神經網路架構已然誕生, 其中之一就是編解碼架構。這種架構很常用於解決序列到序列轉換問題, 能處理變數長度輸入和輸出,在手寫辨識的類似領域(例如語音辨識)更成為尖端科技。 編解碼系統的關鍵優點,在於整個模型接受了完整訓練,而非每個元素都分開訓練。 可採用的架構有好幾種,包括卷積神經網路層、遞迴神經網路層、長短期記憶單元(簡稱 LSTM),以及常用於變形(Transformer)模型的專注層(以上僅列舉幾例)。
以我們的情況來說,編解碼架構的輸入內容是一連串座標,代表手寫筆跡的軌跡。 至於輸出,則是一系列辨識出來的字元,以 LaTeX 符號表示,例如 x^2 代表 x²,或以 (\frac{ }) 代表分數。


人工智慧手寫技術的未來
手寫辨識技術的演進還很漫長。 我們已經著手擴充人工智慧的能力,以便解決各種問題,包括自動語言辨識和互動手寫表格。
我們認為深度學習模型的發展潛力無限,也可能讓我們得以統一之前不相關研究領域的做法,例如自然語言處理和排版分析。 由於擁有觸控功能的數位裝置日益普及,所以我們相信人工智慧一定能讓我們從「辨識眼睛所見」,進步到能夠「辨識原意」。 雖然在內頁上的差別可能很小,但事實上卻代表另一個典範轉移,我們希望能協助達到這一點。
我們的目標,是讓大家用自選裝置建立任何內容,不但要跟在紙上書寫一樣自由,也要保留數位科技的所有功能和彈性。 人工智慧的威力讓這個目標漸漸實現。
