AI 的重要性
AI 是“人工智能”(Artificial Intelligence) 的简称。 它指示计算机科学领域,涉及创造能够复制和增强人脑某些能力(如阅读、理解或分析)的智能机器。
MyScript 的 AI
我们的核心软件产品由专有的 AI 技术提供支持。 我们利用 AI 解读 70 多种语言的手写内容,分析手写笔记的结构,理解数学方程式,甚至识别和转换手绘的乐谱。
我们的技术以 20 余载的研发为依托。 为打造世界上最准确的手写识别引擎,我们对语言形成的细枝末节进行了(并将继续进行)持续研究:单词如何组成句子,字符如何组成单词;变音符号如何置于某些元音之上或之下等等。
MyScript 的多个研究小组通力合作,创建并发展了能够理解各种各样手写内容的一流系统。
文本手写研究
我们的文本手写研究团队使用机器学习技术来解决可表述为序列到序列(简称 seq2seq)转换的问题,例如将手写文本转换为其组成字符。
这些技术必须适应不同的字母和惯例,才能识别从右到左的语言(如阿拉伯语或希伯来语)、印度文字中的变音元音、中文表意文字、韩文谚文字母或竖直排列的日文平假名、片假名或汉字字符。
2D 手写研究
这个团队建立了基于二维解析器和/或语法的数学模型。 他们解决了 seq2seq 方法无法解决的问题,如数学表达式、乐谱或图表的识别。 它们采用基于图形的技术来进行识别,其主要挑战就是实时处理。
自然语言处理研究
我们的自然语言处理 (NLP) 团队开发的算法,能够如任何人类一般自然而然地理解语言。 在该团队使用的文本语料库中,包含从公开的文档和文章中获取的数亿单词。 他们由此建立语言词汇表,精心设计模型来预测句子中的下一个字符,并设计识别和纠正拼写错误的系统。
数据收集
我们的大部分工作之所以得以实现,归功于世界各地的用户自愿分享的匿名样本数据。 这些“训练样本”(在 AI 研究中的叫法)始终受到至高的隐私和安全保护,并且是我们公司的巨大资产,帮助完善和提高我们的技术。
手写识别:挑战
由于手写风格的差异巨大,手写识别存在巨大技术挑战。 书写者的年龄、惯用手、原籍国乃至书写表面等因素都会影响书写,这还没有考虑不同语言和字母的影响。
为阐明其中的挑战:优秀的手写识别软件应当能够从 30,000 多个可能的表意文字中分辨出一个汉字。 它还必须能够识别和解码双向书写 - 这样在使用从右到左书写语言(如阿拉伯语或希伯来语)的书写者在内容中包含一些从左到右的外语单词时,也能继续正常进行。
软件难以对连写手写体进行分节并识别单个字符,延迟的笔划(如变音符号)则更是容易造成混淆。 这种笔记的布局常常结构凌乱,导致自动分析内容变得更加棘手 - 就如包含数学表达式、图表和表格等其它类型的内容一样。
时间也是因素之一:手写识别软件必须实时工作,随着用户书写来解读其输入。 如果用户在书写时编辑内容,例如勾除某个字来将其擦除,插入一个空格或移动一段,识别引擎必须能够随之跟进。
此外,手写识别技术必须能够分析排版字符以及手写笔划,这样用户就能导入网页或其它应用程序中的输入文本,然后在需要之处手写批注。 优秀的识别引擎必须准确解读这种复杂的互动,区分编辑笔势、添加的变音符号或书写的新字符和新词。
投资于神经网络
20 多年前,当全球手写识别研究界集中精力研究隐马尔可夫模型 (HMM) 和支持向量机 (SVM) 时,MyScript 却另辟蹊径。
我们选择主攻神经网络。
神经网络是一种模仿人脑学习过程的机器学习类型。 在强大的算法驱动下,神经网络可识别庞大数据集中的模式,从而对我们研究的任何事物(如手写)进行更准确的泛化。
神经网络由“经过训练”的数学模型构建而成,可根据预先确定的变量或“维度”识别各种模式。 精心编程的算法则根据这些维度反复对数据进行拆分和排序,分类和重新分类,直至出现明确的模式。
通过这种方式,神经网络可以执行人类不可能完成的任务。 它们快速筛选大量数据,突出显示可能会被忽视的模式。 我们相信,我们利用神经网络可以训练出世界上有史以来最准确、最先进的手写识别引擎。
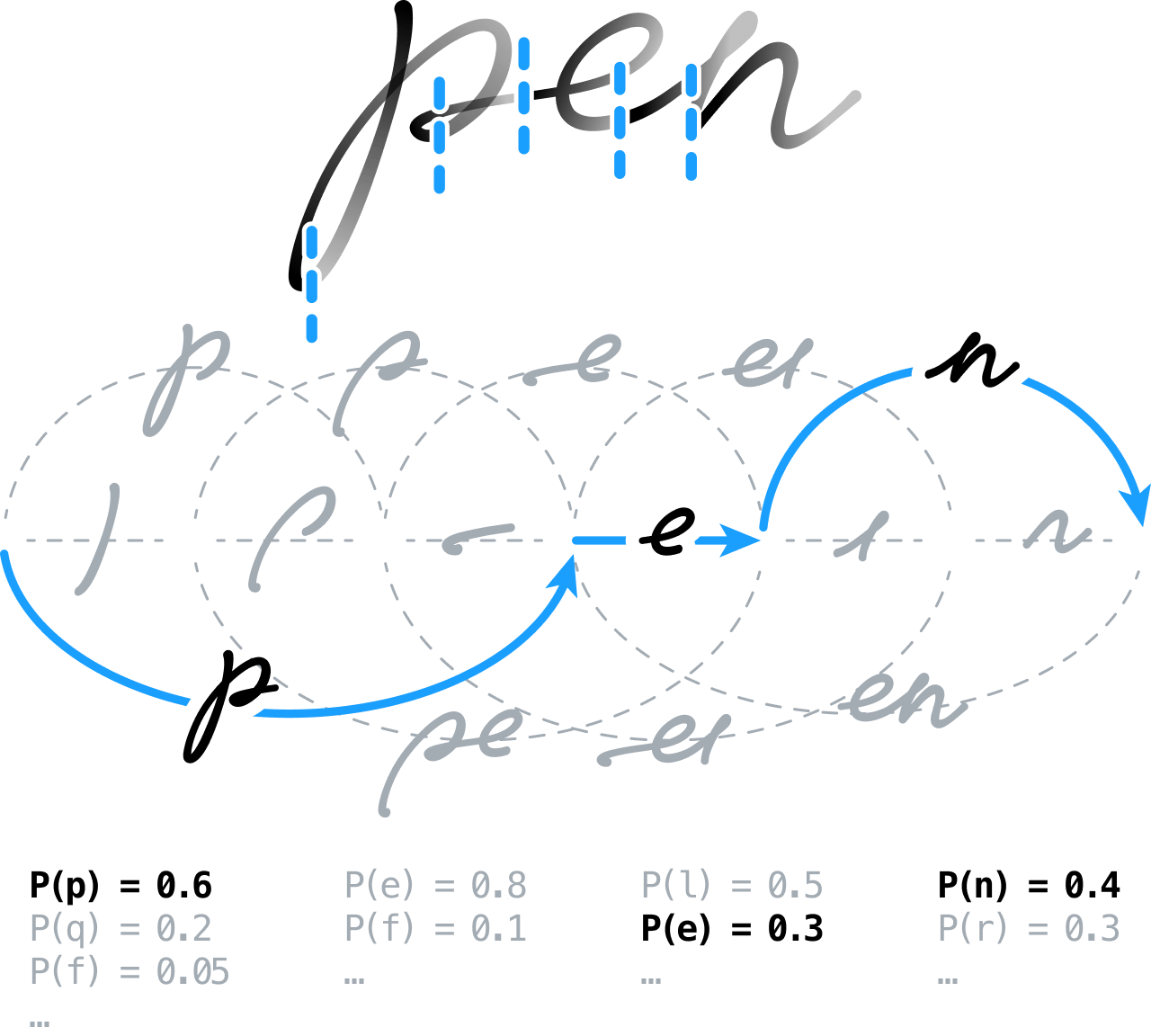
使用神经网络识别手写体
从一开始,我们的构思就是对手写内容进行预处理,为分析做好准备,执行提取线条、规范笔画和纠正倾斜等任务。 然后对信号进行反复分节,让识别引擎决定字符和单词之间的边界位置。
这意味着对所有可能的分节进行建模,来有效建立分节图,将连续的节按字符假设分组,然后通过前馈神经网络进行分类。 我们采用了一种基于全局区分性训练机制的新方法。 如今这种技术在连接时序分类 (CTC) 框架中相当普遍,用于训练序列到序列的神经系统。
我们还建立并采用了一种最先进的统计语言模型,其中包含词汇、语法和语义信息,可用于澄清和解决不同候选字符之间一些遗留的不确定性。
为 2D 语言训练 AI
我们在神经网络方面的成功,有利于我们为印刷体和连写体打造全球顶级的手写识别引擎。 但有些语言更为复杂,于是乎就带来了下一个挑战。
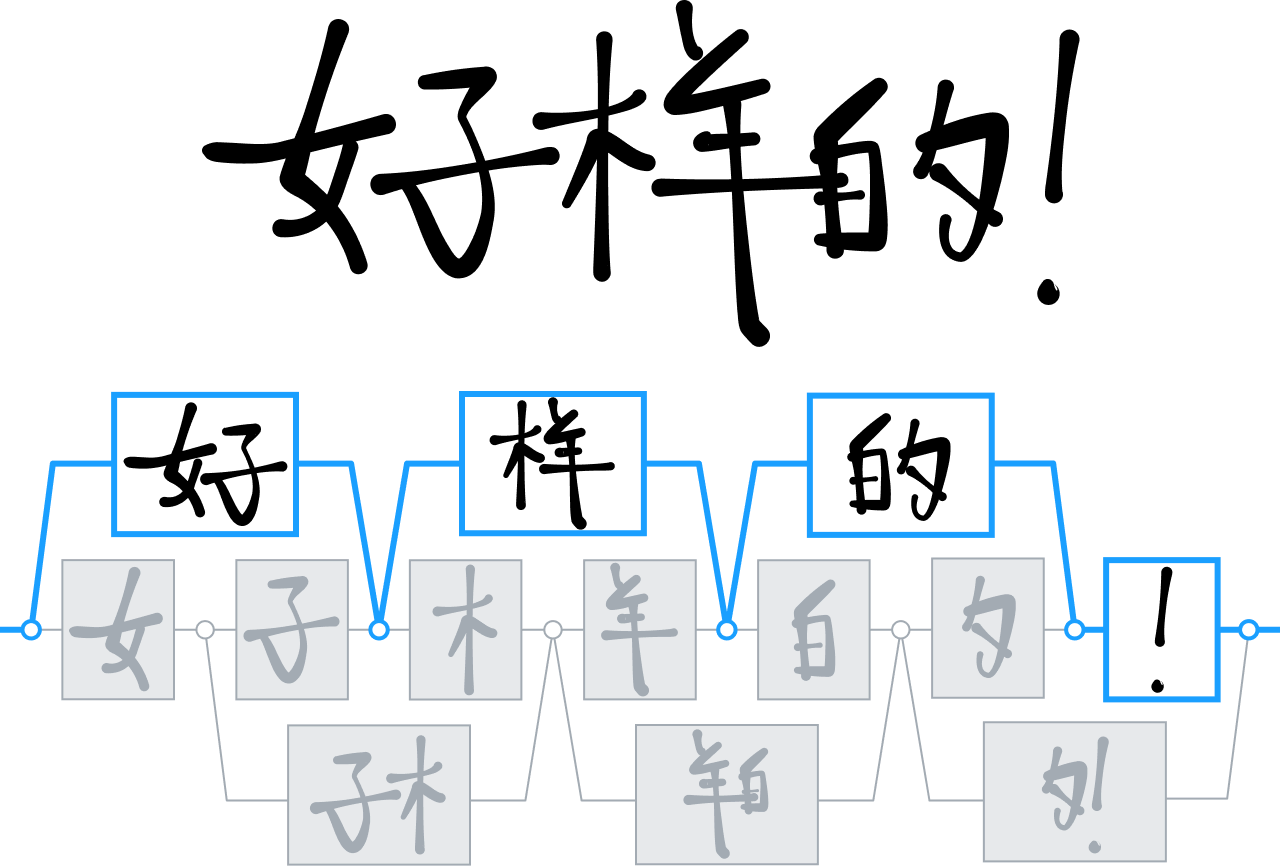
汉字识别
多年来,MyScript 开发了一系列用于分析和解读二维语言的技术 - 尤其是中文表意文字。
该领域的大多数竞争对手都在使用决策树技术来区分和解读汉字,而我们却在神经网络方面倍加努力,训练我们的引擎来识别 30,000 多个表意文字。
这是一个研究团队第一次成功地训练如此庞大的网络,幕后功臣就是浩大的数据收集活动,该活动收集了有史以来规模最大的手写中文数据集。
我们利用这些数据开发了一种专门利用汉字结构的新型神经架构;此外还整合了一项专门的聚类技术来加快处理时间。 有了这些创新,我们得以为键盘输入仍很困难且有失灵活的市场提供新高度的手写识别。 我们也得以为日语、印地语和韩语等其它语言增添同样水平的支持。
数学识别
在成功运用神经网络分析和识别一系列世界语言之后,新的目标出现了:数学表达式的识别。
常规语言为字符和单词的结构序列,而二维(或视觉)语言通常更适合用节点之间存在空间关系的树状或图形结构来描述。 与文本一样,我们的数学识别系统所依循的原则是:分节、识别、语法和语义分析必须在同一层级并发处理,以产生最佳识别备选项。
该系统根据特定的专用语法中规定的规则,来分析数学方程式所有部分之间的空间关系,然后据此分析来确定分节。 语法本身包括一套描述如何解析方程式的规则,其中每条规则都与特定的空间关系相关。 例如,分数规则定义分子、分数线和分母之间的垂直关系。
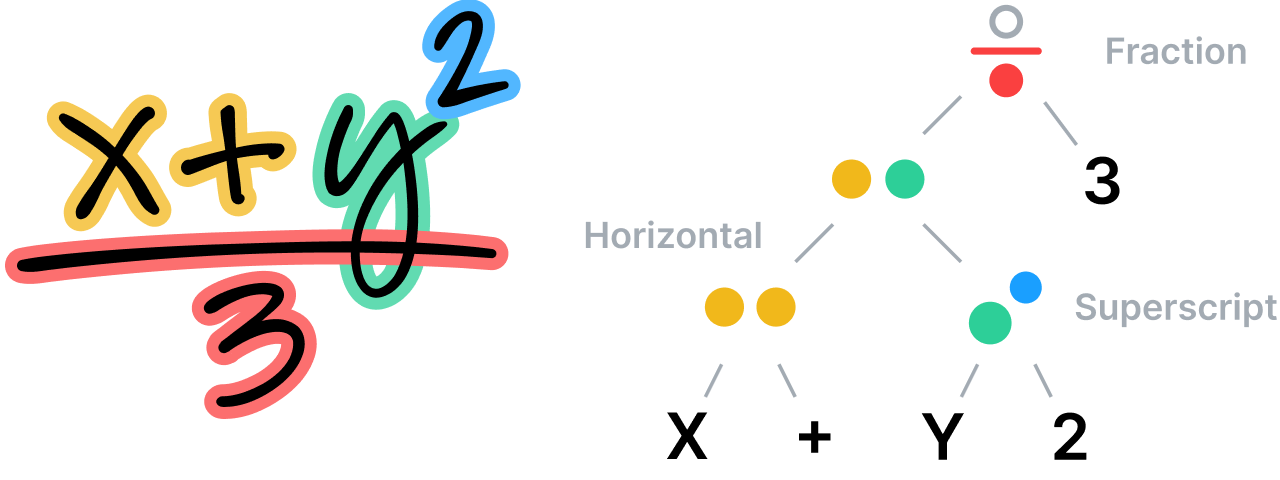
理解结构凌乱的笔记
由于能对数学表达式进行准确即时的识别,因而在手写笔记的布局和内容方面开拓了新的可能。
如果我们的识别引擎能够正确解读数学方程式各部分之间的空间关系,它是否也能准确识别非文本内容的类型呢? 如果是这样,我们就可以开始克服结构凌乱的笔记所带来的问题,利用我们的技术准确识别乃至美化手绘图表等元素。
我们认为,图神经网络 (GNN) 架构非常适合这样的任务。 其基本理念就是将整个文档作为一个图来建模,其中笔划用节点表示,并通过边连接到相邻笔划。
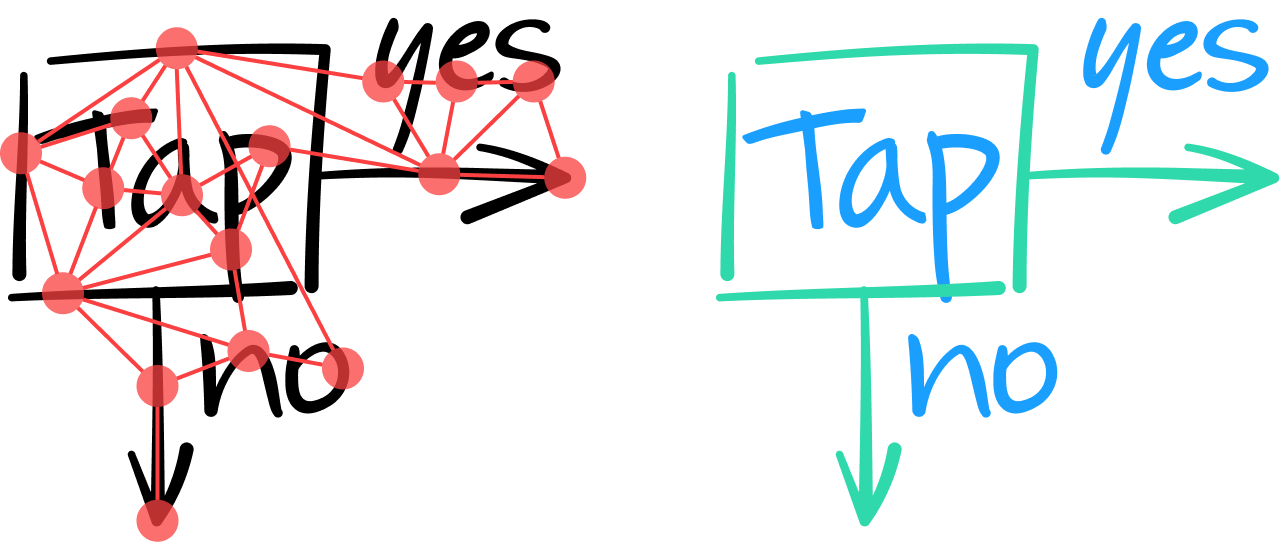
以这种方式分析笔记内容时,GNN 必须将所有笔划作为文本或非文本分类。 其实现方式就是分析每个笔划的内在特征,并在必要时考虑笔划邻边和相邻节点所提供的上下文信息。
GNN 中的一层将一个节点的特征与其相邻节点的特征结合起来,生成一个代表高层次特征的数值向量。 与卷积神经网络一样,几个层可以堆叠,来提取越来越多的全局特征,从而对一个笔划是否构成文本笔划作出更明智的决定。 例如,下图中最左边的两条竖线看起来相似;只有整合其相邻笔划的上下文信息,GNN 才能(在输出层)分类得出最左边的笔划是一个几何方形的一部分,而旁边的笔划是字符“T”的一部分。
深度学习和编码器-解码器模型
提供纸质书写和数字化书写识别这两个一流系统来识别文字和数学并不总是很充分 - 对于在科学领域工作或学习的用户更是如此。 这类用户时常需要将内联数学作为连续文本的一部分来书写(即不在该页面上的某个单独空间),他们希望识别引擎能正确解读这两种情况。
这一挑战在于设计一种能够识别字符和单词与数学表达式相混合的系统 - 即分析自然单维语言(文本)和二维语言(数学)的组合。
在深度学习浪潮的席卷之下,新的神经网络架构应运而生。 其中的编码器-解码器经常用于解决序列到序列转换的问题。 它可以处理可变长度的输入和输出,成为语音识别等接近手写识别领域最先进的技术。 编码器-解码器系统的关键优势是整个模型进行端到端训练,并非单独训练每个元素。 多种架构都能使用,包括卷积神经网络层、递归神经网络层、长短期记忆单元 (LSTM) 和 Transformer 模型中常用的基于注意力的层(仅举几例)。
在我们的案例中,编码器-解码器的输入是一串代表手写笔划轨迹的坐标。 输出则是一串以 LaTeX 符号形式出现的识别字符(例如,用 x^2 代替 x²,或用 (\frac{ }) 代替分数)。
AI 手写的未来
手写识别技术方兴未艾。 我们已经在努力扩展 AI 的能力,目的是让它能够解决包括自动语言识别和交互式手写表格在内的问题。
我们相信,深度学习模型提供了巨大的发展潜力,并且能帮助我们在自然语言处理和布局分析等以前不相关的研究领域中也统一使用该方法。 结合日益普遍的触屏数字设备,我们相信 AI 将助力我们从“识别所见”转变为“识别本意”。 这种差异在页面上可能看起来不明显,但其实这代表另一种范式转变。而我们也有意帮助实现这一目标。
我们的愿景是打造一个这样的世界:任何人在他们选择的设备上,都能像在纸上一样随心所欲地创建任意类型的内容,同时保留数字化的全部力量和灵活性。 在 AI 的助力下,这一愿景每天都在向现实靠近。
