IA, réseaux de neurones et reconnaissance d'écriture
L'IA transforme notre compréhension de la manière dont les gens écrivent, et propulse la technologie d'écriture numérique vers de nouveaux sommets
L'importance de l'IA
Le terme IA est l'abréviation d'intelligence artificielle. Il fait référence au domaine de l'informatique dédié à la création de machines intelligentes capables de reproduire et d'améliorer certaines capacités du cerveau humain, telles que la lecture, la compréhension ou l'analyse.
L'IA chez MyScript
Nos produits logiciels de base sont alimentés par une technologie d'IA propriétaire. Nous utilisons l'IA pour interpréter le contenu manuscrit dans plus de 70 langues, pour analyser la structure de notes manuscrites, pour interpréter des équations mathématiques et même pour reconnaître et convertir des notations musicales.
Notre techno s'appuie sur plus de 20 ans en recherche et développement. Pour créer le moteur de reconnaissance d'écriture manuscrite le plus précis au monde, nous avons mené (et continuons de mener) des recherches permanentes sur les concepts de la formation du langage et de l'écriture : comment les phrases sont construites à partir de mots et les mots à partir de caractères ; comment les signes diacritiques sont placés au-dessus ou au-dessous de certaines voyelles, etc.
Chez MyScript, plusieurs groupes de chercheurs·euses collaborent pour créer et faire évoluer un système de pointe, capable de comprendre une gamme considérable de contenus manuscrits.
Recherche sur le texte manuscrit
Notre équipe de recherche sur le texte manuscrit utilise des techniques de machine learning pour résoudre des problèmes qui peuvent être formulés comme des problèmes de conversion séquence à séquence (ou seq2seq), comme lors de la conversion d'un texte manuscrit en ses caractères constitutifs.
Les techniques doivent être adaptées aux différents alphabets et conventions, pour permettre la reconnaissance, par exemple, des langues s'écrivant de droite à gauche comme l'arabe ou l'hébreu, des idéogrammes chinois, de l'alphabet Hangul coréen ou le mélange de 3 alphabets en japonais (hiragana, katakana, kanji).
Recherche sur l'écriture manuscrite 2D
Cette équipe construit des modèles mathématiques basés sur des grammaires et/ou des parseurs bidimensionnels. Ils et elles traitent des problèmes qui ne peuvent pas être résolus par les approches seq2seq, comme la reconnaissance d'expressions mathématiques, de notations musicales ou de diagrammes et de graphiques. Ils et elles utilisent des techniques basées sur des graphes pour permettre la reconnaissance, le traitement en temps réel constituant un défi majeur.
Recherche en Traitement Automatique des Langues
Notre équipe de Traitement Automatique des Langues (TAL) développe des algorithmes capables de comprendre les langues aussi naturellement que n'importe quel être humain. L'équipe utilise des corpus textuels contenant des centaines de millions de mots obtenus à partir de documents et d'articles accessibles au public. À partir de là, ils et elles construisent des vocabulaires linguistiques, élaborent des modèles pour prédire le prochain caractère dans une phrase et conçoivent des systèmes d'identification et de correction de fautes d'orthographe.
Collecte de données
Une grande partie de notre travail est rendue possible par des échantillons de données anonymes que des utilisateurs·trices du monde entier partagent volontairement avec nous. Ces « échantillons d'apprentissage » (tels que communément appelés dans le domaine de l'IA) sont toujours traités avec le plus grand respect de leur confidentialité et sécurité, et constituent un atout considérable pour l'entreprise, nous aidant à affiner et à améliorer notre technologie.

Reconnaissance d'écriture : les défis
La reconnaissance d'écriture manuscrite pose des défis techniques importants en raison de la grande variabilité des styles d'écriture. Des facteurs tels que l'âge du scripteur ou de la scriptrice, sa latéralité, son pays d'origine et même la surface d'écriture peuvent avoir un impact sur l'écriture qu'il ou elle produit, et ce avant même de prendre en compte les effets des différentes langues et alphabets.
Pour illustrer les enjeux : un logiciel de reconnaissance d'écriture doit être capable de distinguer un seul caractère chinois parmi plus de 30 000 idéogrammes possibles. Il doit également être capable de reconnaître l'écriture bidirectionnelle, contenues dans les langues comme l'arabe et l'hébreu, afin d'identifier lorsque l'utilisateur·trice écrivant naturellement de droite à gauche inclut dans son contenu des mots étrangers s'écrivant de gauche à droite.
L'écriture cursive rend difficile les tâches de segmentation et la reconnaissance des caractères individuels pour le système, tandis que les traits différés (comme les signes diacritiques) ajoutent des possibilités de confusion supplémentaires. Les mises en page non structurées de ces notes rendent l'analyse automatique de document beaucoup plus délicate, tout comme l'inclusion d'autres types de contenu, tels que des expressions mathématiques, des graphiques et des tableaux.
Le temps de traitement est également un facteur majeur : le logiciel de reconnaissance d'écriture doit fonctionner en temps réel, interprétant la saisie de l'utilisateur·trice au fur et à mesure qu'il ou elle écrit. Si l'utilisateur·trice modifie son contenu en cours d'écriture – par exemple, en raturant un mot pour l'effacer, en insérant un espace ou en déplaçant un paragraphe – le moteur de reconnaissance doit pouvoir en tenir compte.
De plus, la technologie de reconnaissance d'écriture doit être capable d'analyser les caractères saisis au clavier, eux-mêmes mixés au contenu manuscrit, afin qu'un·e utilisateur·trice puisse importer du texte à partir de pages web ou d'autres apps, puis l'annoter à la main si nécessaire. Le moteur de reconnaissance doit interpréter ces interactions complexes avec précision, en distinguant les gestes d'édition, l'ajout de signes diacritiques ou l'écriture de nouveaux caractères et mots.
Investir dans les réseaux de neurones
Il y a plus de 20 ans, lorsque la communauté internationale de recherche sur la reconnaissance d'écriture manuscrite concentrait ses efforts sur les modèles de Markov cachés (MMC) et les machines à vecteurs de support (SVM), MyScript a choisi d'emprunter une voie différente.
Nous nous sommes concentré·e·s sur les réseaux de neurones.
Un réseau de neurones est un type de machine learning qui imite les processus d'apprentissage du cerveau humain. Piloté par de puissants algorithmes, un réseau de neurones identifie des patterns dans de vastes ensembles de données, permettant des généralisations plus précises sur tout ce que nous étudions, comme l'écriture manuscrite.
Les réseaux de neurones sont construits à partir de modèles mathématiques qu'on « entraîne » à identifier des patterns en fonction de variables prédéterminées, ou « dimensions ». Des algorithmes soigneusement programmés séparent et trient à plusieurs reprises les données en fonction de ces dimensions, classant et reclassant jusqu'à ce que des patterns clairs apparaissent.
De cette façon, les réseaux de neurones peuvent effectuer des tâches qui seraient impossibles pour les êtres humains. Ils passent au crible d'énormes quantités de données à grande vitesse, mettant en évidence des patterns qui pourraient autrement échapper à l'attention. Nous étions convaincu·e·s que nous pouvions utiliser les réseaux de neurones pour créer le moteur de reconnaissance d'écriture le plus précis et le plus avancé que le monde ait jamais vu.
Utiliser les réseaux de neurones pour reconnaître l'écriture manuscrite
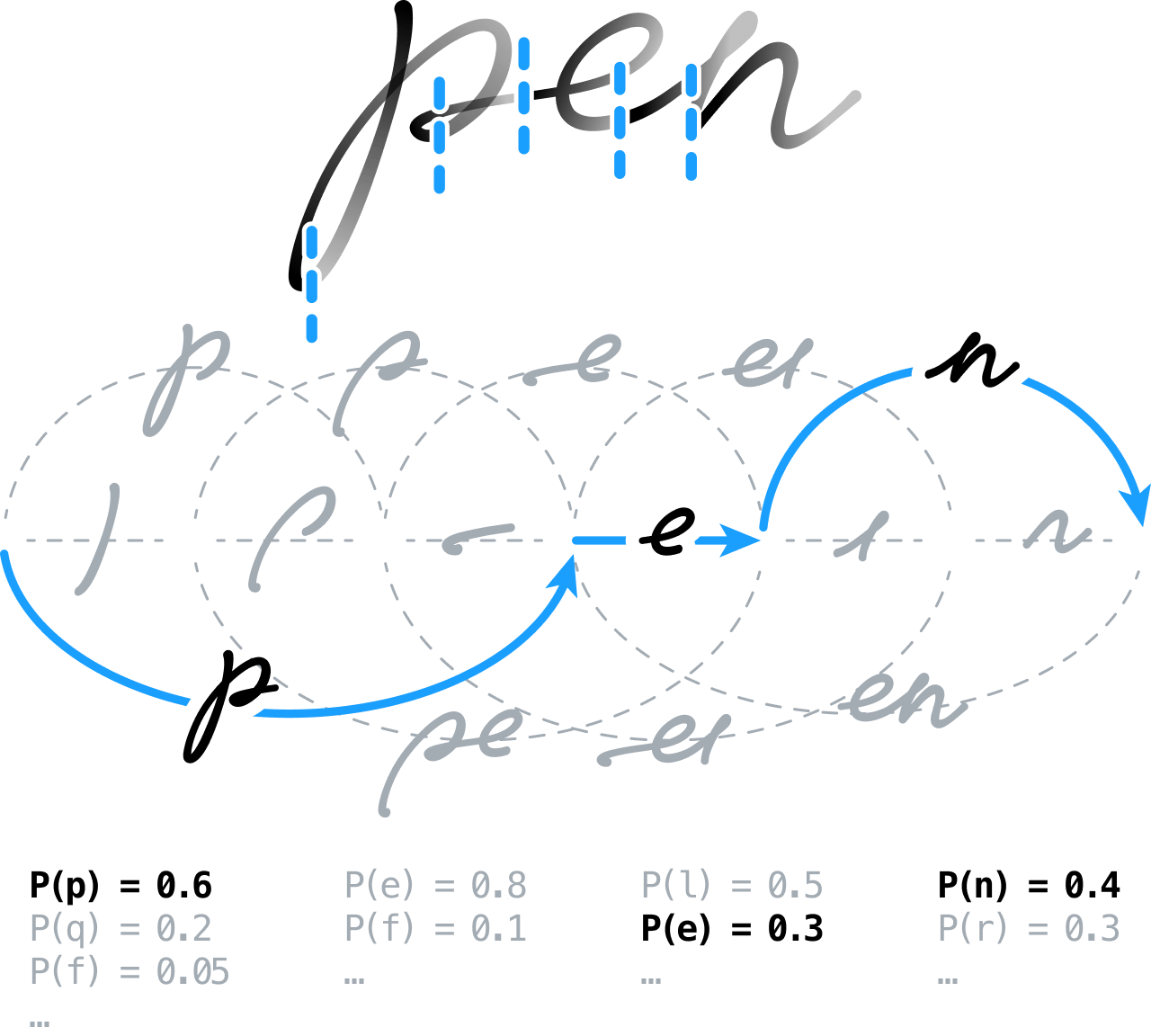
Notre idée de départ était de prétraiter le contenu manuscrit pour le préparer à l'analyse, en effectuant des opérations telles que l'extraction de lignes, la normalisation de l'encre et la correction de l'inclinaison de l'écriture. Nous avons alors sur-segmenté le signal et laissé le moteur de reconnaissance décider ensuite de la position des limites entre les caractères et les mots.
Cela signifiait construire un graphe de segmentation en modélisant toutes les segmentations possibles, c'est-à-dire en regroupant les segments contigus en hypothèses de caractères qui étaient ensuite classées au moyen de réseaux de neurones à propagation avant. Nous avons utilisé une nouvelle approche basée sur une méthode d'apprentissage global discriminant. De nos jours, cette technique est assez couramment employée dans le cadre de la Classification Temporelle Connexionniste (CTC), pour entraîner des systèmes neuronaux séquence à séquence.
Nous avons également construit et utilisé des modèles de langage statistiques de pointe incorporant des informations lexicales, grammaticales et sémantiques pour résoudre certaines ambiguïtés restantes entre les différentes interprétations de caractères.

Étendre l'IA aux langages 2D
Notre succès avec les réseaux de neurones nous a permis de construire le meilleur moteur de reconnaissance au monde pour l'écriture script ou cursive. Mais certaines langues présentent une complexité encore plus grande, ce qui nous a amené·e·s au défi suivant.
Reconnaissance des caractères chinois
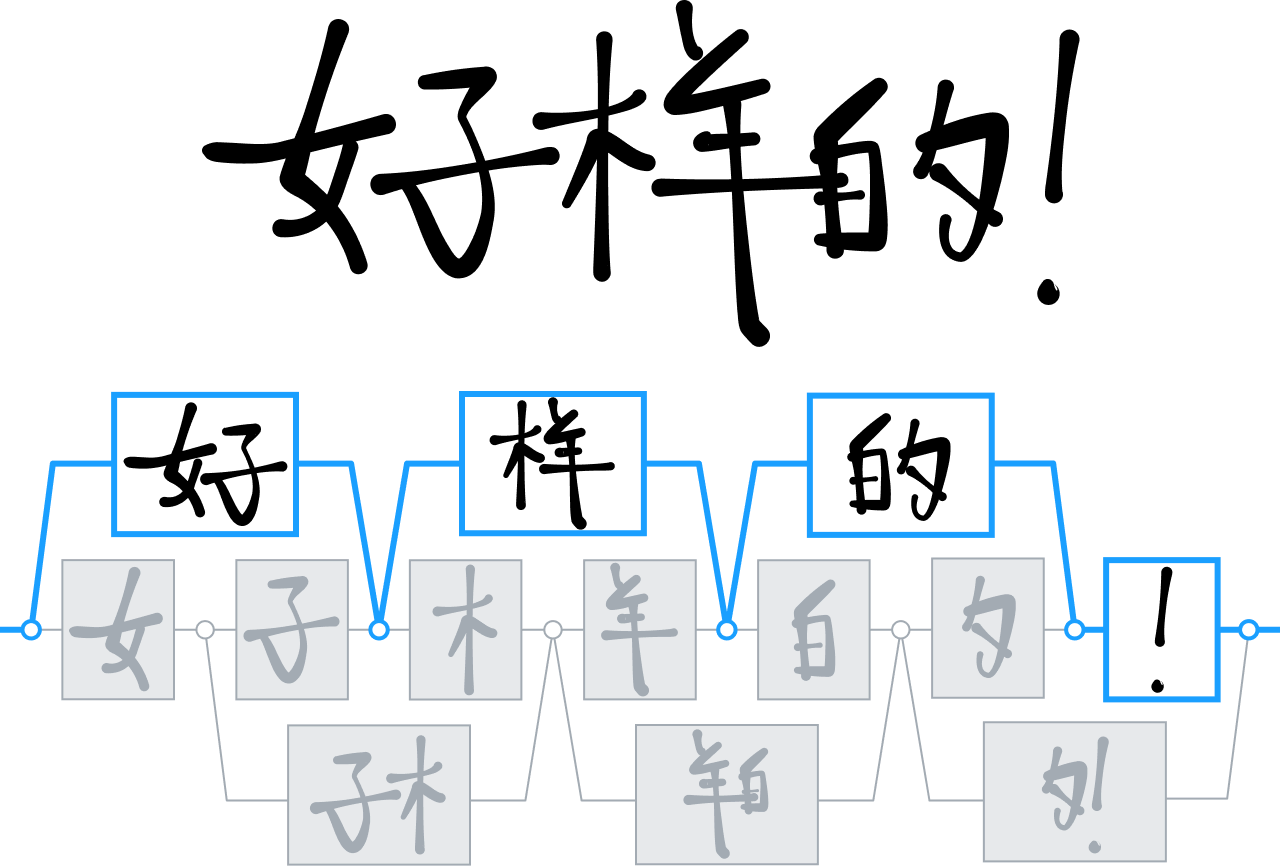
Au fil des années, MyScript a développé une gamme de technologies pour analyser et interpréter les langages visuels et bidimensionnels, notamment pour la reconnaissance des idéogrammes chinois.
Alors que la plupart de nos concurrents utilisaient des techniques d'arbre de décision pour différencier et interpréter les caractères chinois, nous avons misé à nouveau sur les réseaux de neurones, entraînant notre moteur à reconnaître plus de 30 000 idéogrammes.
C'était la première fois qu'une équipe de recherche réussissait à entraîner un réseau de cette taille, grâce à une immense campagne de collecte de données produisant la plus grande base de caractères chinois manuscrits jamais vue.
Nous avons utilisé ces données pour développer une nouvelle architecture neuronale qui exploite spécifiquement la structure bidimensionnelle des caractères chinois. Nous avons également intégré une technique spécialisée de clustering pour accélérer les temps de traitement. Ces innovations nous ont permis d'offrir un niveau de reconnaissance d'écriture jamais atteint sur un marché chinois où la saisie au clavier reste pénible et peu flexible. Niveau que nous avons également atteint pour d'autres langues telles que le japonais, l'hindi et le coréen.
Reconnaissance des maths
Après avoir utilisé avec succès des réseaux de neurones pour analyser et reconnaître une multitude de langues, un nouvel objectif est apparu : la reconnaissance d'expressions mathématiques.
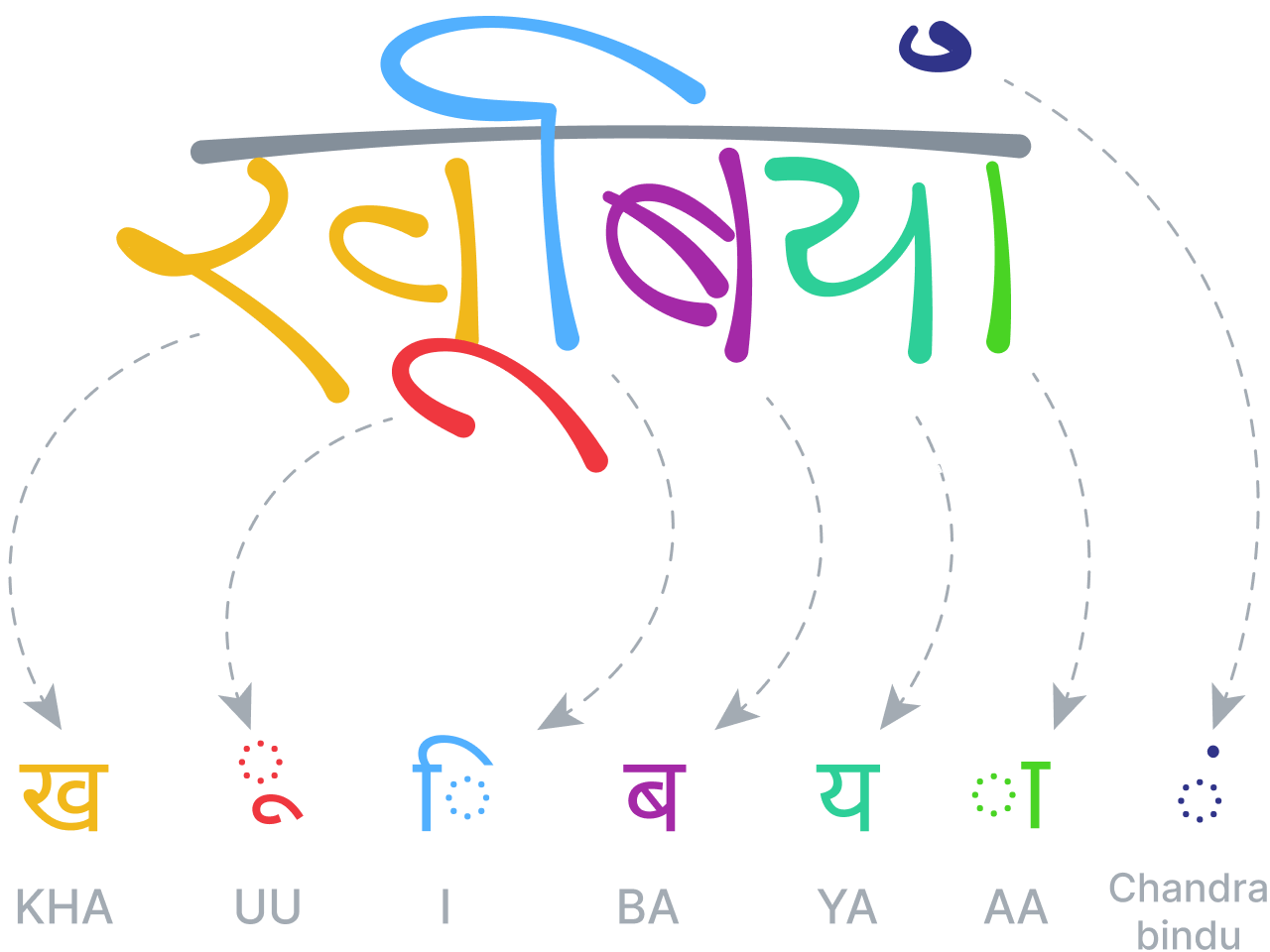
Là où les langues possèdent des séquences structurelles de caractères et de mots, les langages bidimensionnels (ou visuels) sont souvent mieux décrits par une structure arborescente ou graphique, avec des relations spatiales entre les nœuds. Comme pour le texte, notre système de reconnaissance des mathématiques est construit sur le principe que la segmentation, la reconnaissance, ainsi que l'analyse grammaticale et sémantique doivent être traitées simultanément et au même niveau, afin de produire les meilleurs résultats de reconnaissance.
Le système analyse les relations spatiales entre toutes les parties d'une équation mathématique, conformément aux règles définies dans sa grammaire spécifique et spécialisée, puis utilise cette analyse pour déterminer la segmentation. La grammaire elle-même comprend un ensemble de règles décrivant comment analyser une équation, chaque règle étant associée à une relation spatiale spécifique. Par exemple, une règle de fraction définit une relation verticale entre un numérateur, une barre de fraction et un dénominateur.
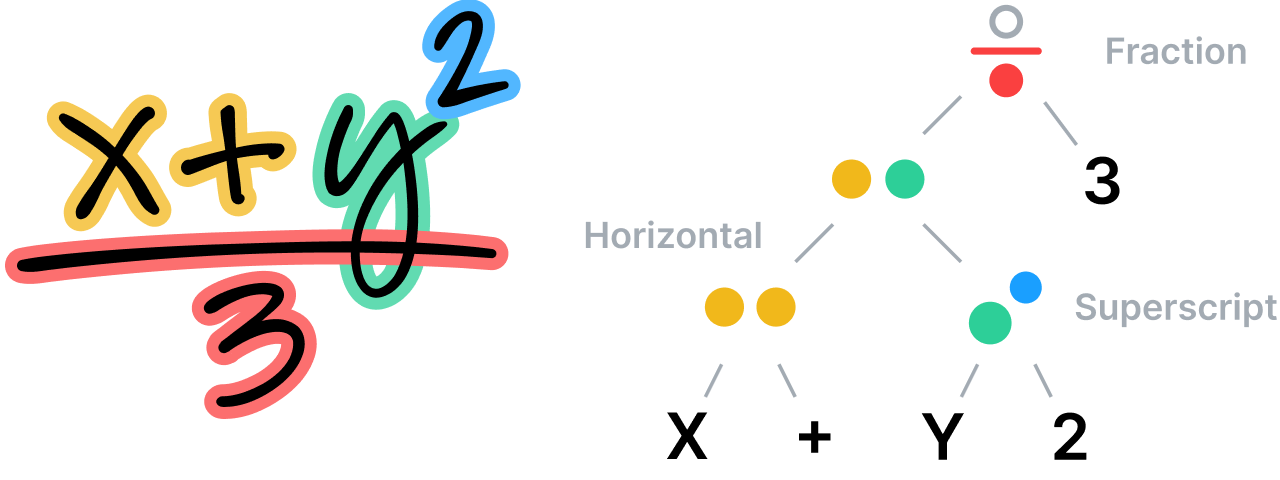
Comprendre les notes non structurées
La reconnaissance automatique des expressions mathématiques a ouvert de nouvelles possibilités liées à l'analyse de la mise en page et du contenu des notes manuscrites.
Si notre moteur de reconnaissance pouvait interpréter correctement les relations spatiales entre les parties d'une équation mathématique, pourrait-il également identifier avec précision les types de contenu non textuel ? Dans ce cas, nous pourrions commencer à surmonter les problèmes posés par les notes non structurées, en utilisant notre technologie pour identifier avec précision et même embellir des éléments tels que des diagrammes dessinés à la main.
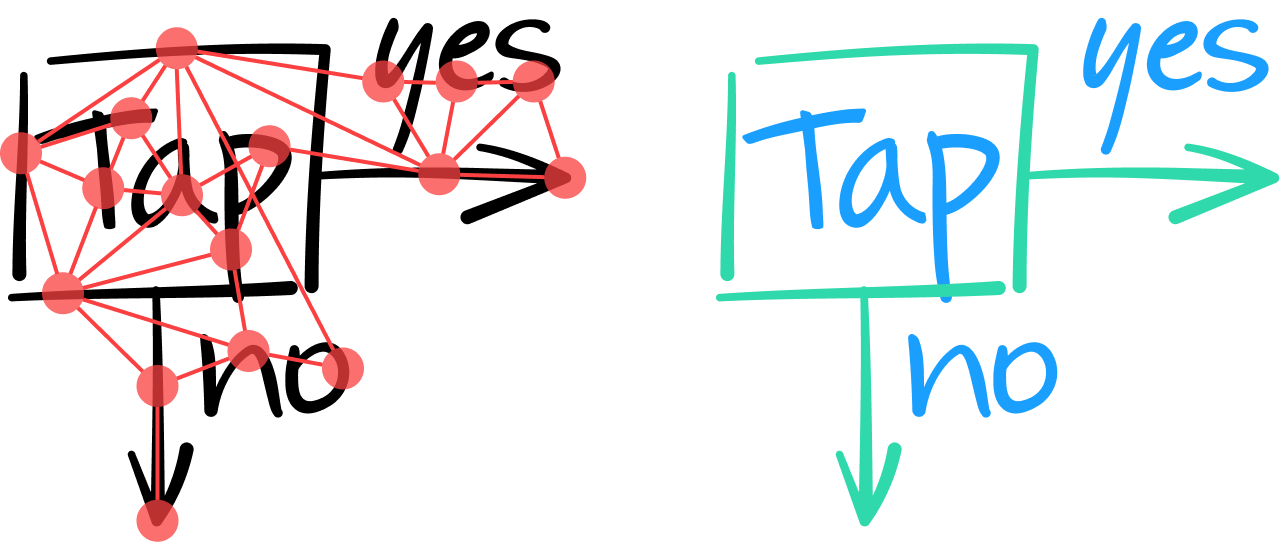
Nous pensions que les architectures de réseaux neuronaux en graphes (GNN) étaient appropriées pour une telle tâche. L'idée de base est de modéliser un document entier sous forme de graphe, où les traits sont représentés par des nœuds et sont reliés par des arêtes à leurs traits voisins.
En analysant ainsi le contenu d'une note, le GNN doit classer tous les traits comme texte ou non-texte. Pour cela, il analyse les caractéristiques intrinsèques de chaque trait, et si besoin, prend en compte les informations contextuelles fournies par les arêtes et nœuds voisins d'un trait.
Une couche du GNN combine les caractéristiques d'un nœud avec celles de ses voisins pour produire un vecteur de valeurs numériques représentant des caractéristiques de niveau supérieur. Comme pour les réseaux de neurones convolutifs, plusieurs couches peuvent être empilées pour extraire un nombre croissant de caractéristiques globales, permettant ainsi une décision plus pertinente pour déterminer si un trait est issu d'un bloc textuel ou plutôt d'une entité graphique. Par exemple, dans le diagramme suivant, les deux traits verticaux les plus à gauche semblent similaires ; ce n'est qu'en intégrant les informations contextuelles des traits voisins que le GNN peut classifier (au niveau de la couche de sortie) que le trait le plus à gauche fait partie d'une forme géométrique carrée, tandis que celui de droite fait partie de la lettre "T".
Deep Learning et modèle encodeur-décodeur
Il ne suffit pas toujours de proposer deux systèmes de pointe pour reconnaître le texte et les mathématiques, en particulier pour les personnes qui travaillent ou étudient dans les domaines scientifiques. Ces utilisateurs·trices ont souvent besoin d'écrire des maths au milieu d'une ligne de texte (et pas dans un espace séparé sur la page), et ils et elles attendent du moteur de reconnaissance qu'il interprète les deux correctement.
Le défi consistait donc à concevoir un système capable de reconnaître des caractères et des mots mélangés à des expressions mathématiques, c'est-à-dire d'analyser la combinaison d'un langage naturel unidimensionnel (texte) et d'un langage bidimensionnel (maths).
Avec la vague du Deep Learning, de nouvelles architectures de réseaux de neurones sont apparues. Parmi celles-ci, l'encodeur-décodeur est devenu très populaire pour résoudre les problèmes de conversion séquence à séquence. Il peut gérer des entrées et des sorties de longueur variable, et est devenu la référence dans des domaines proches de la reconnaissance d'écriture, comme la reconnaissance vocale. Le principal avantage d'un système encodeur-décodeur est que l'ensemble du modèle est entraîné de bout en bout, au lieu d'entraîner chaque élément séparément. Plusieurs architectures peuvent être utilisées, notamment les couches de réseaux de neurones convolutifs, les couches de réseaux de neurones récurrents, les cellules de mémoire de type LSTM (Long Short-Term Memory) et les couches basées sur des dispositifs d'attention, couramment utilisées dans le modèle Transformer (pour n'en citer que quelques-unes).
Dans notre cas, l'entrée de l'encodeur-décodeur est une séquence de coordonnées représentant la trajectoire des traits réalisés au stylet. La sortie est une séquence de caractères reconnus sous forme de symboles LaTeX (par exemple, x^2 pour x² ou (\frac{ }) pour une fraction).


L'avenir de l'écriture manuscrite IA
L'évolution de la technologie de reconnaissance d'écriture est loin d'être terminée. Nous travaillons déjà à étendre les capacités de notre IA afin qu'elle puisse résoudre des problèmes comme l'identification automatique des langues et l'interprétations des tableaux pour les rendre éditables.
Nous pensons que les modèles de Deep Learning offrent un énorme potentiel de développement, et pourraient nous permettre d'unifier notre approche dans des domaines de recherche jusqu'ici dissociés, comme l'analyse automatique des langues et l'analyse automatique de documents. Avec l'omniprésence grandissante des appareils numériques tactiles, nous sommes convaincus que l'IA nous permettra de passer de la « reconnaissance visuelle » à la « reconnaissance intentionnelle ». La différence peut sembler subtile sur la page, mais en réalité, cela représente un nouveau changement de paradigme. Et nous sommes déterminé·e·s à contribuer à sa réalisation.
Notre vision est celle d'un monde où chacun·e peut créer n'importe quel type de contenu sur l'appareil de son choix aussi librement que sur papier, en conservant toute la puissance et la flexibilité du numérique. Grâce à la puissance de l'IA, cette vision se rapproche chaque jour un peu plus de la réalité.
