Inteligencia artificial, redes neuronales y reconocimiento de escritura
La inteligencia artificial está transformando nuestra comprensión sobre cómo escriben las personas y está impulsando nuevos avances en la tecnología digital de la escritura a mano.
La importancia de la inteligencia artificial
La inteligencia artificial suele abreviarse como IA. Se refiere al campo de la informática que se ocupa de la creación de máquinas inteligentes capaces de reproducir y mejorar ciertas capacidades del cerebro humano, como la lectura, la comprensión o el análisis.
La inteligencia artificial en MyScript
Nuestros principales productos de software funcionan con tecnología de inteligencia artificial propia patentada. Usamos la IA para interpretar el contenido manuscrito en más de 70 idiomas, analizar la estructura de las notas, interpretar ecuaciones matemáticas e incluso reconocer y convertir la notación musical dibujada a mano.
Nuestra tecnología está respaldada por más de 20 años de investigación y desarrollo. Para crear el motor de reconocimiento de escritura a mano más preciso del mundo, hemos realizado (y seguimos haciéndolo) investigaciones continuas sobre los pormenores de la formación del lenguaje: cómo se construyen las frases a partir de palabras y las palabras a partir de caracteres; cómo se colocan los signos diacríticos encima o debajo de ciertas vocales, etc.
En MyScript, varios grupos de investigadores colaboran para crear y desarrollar un sistema de vanguardia capaz de comprender una apreciable variedad de contenidos manuscritos.
Investigación sobre la escritura de texto a mano
Nuestro equipo de investigación de texto manuscrito utiliza técnicas de aprendizaje automático para resolver cuestiones que se pueden formular como problemas de conversión de secuencia a secuencia (o seq2seq), como cuando se convierte el texto manuscrito en los caracteres que lo constituyen.
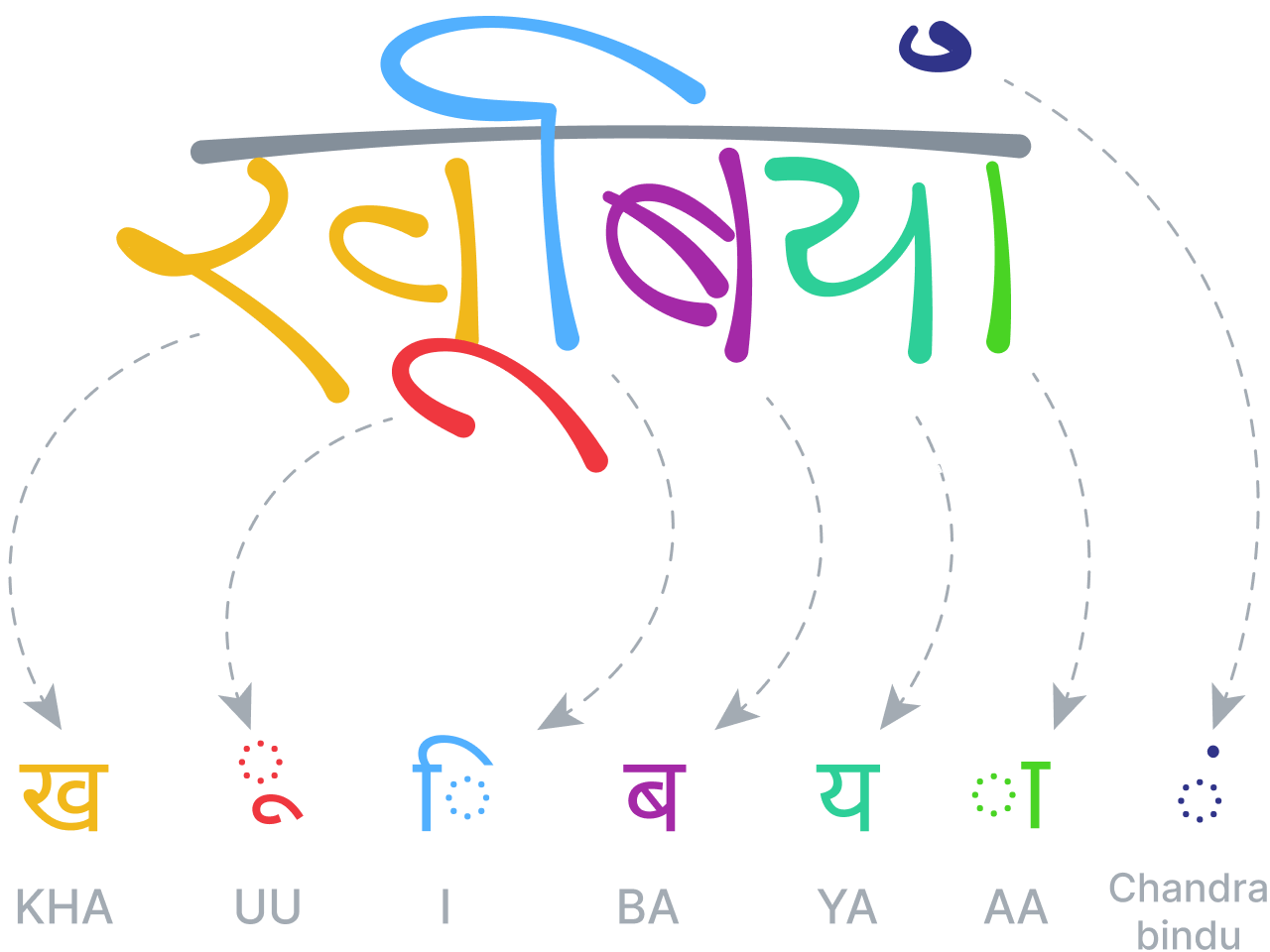
Las técnicas deben adaptarse a distintos alfabetos y convenciones para permitir el reconocimiento de, por ejemplo, idiomas que se escriben de derecha a izquierda como el árabe o el hebreo, las vocales diacríticas de la escritura india, los ideogramas chinos, el alfabeto coreano hangul o los caracteres hiragana, katakana o kanji del japonés secuenciados verticalmente.
Investigación sobre la escritura a mano en 2D
Este equipo construye modelos matemáticos basados en gramáticas y/o analizadores bidimensionales. Abordan problemas que no pueden resolverse con un enfoque seq2seq, como el reconocimiento de expresiones matemáticas, la notación musical o los diagramas y esquemas. Emplean técnicas basadas en gráficos para permitir el reconocimiento. El procesamiento en tiempo real supone un desafío importante.
Investigación en procesamiento del lenguaje natural
Nuestro equipo de procesamiento del lenguaje natural (PLN) desarrolla algoritmos capaces de comprender los lenguajes con la misma naturalidad que un ser humano. El equipo utiliza corpus textuales que contienen cientos de millones de palabras obtenidas de documentos y artículos disponibles públicamente. A partir de ahí, construyen vocabularios lingüísticos, elaboran modelos para predecir el siguiente carácter de una oración y diseñan sistemas que identifican y corrigen faltas ortográficas.
Recopilación de datos
Gran parte de nuestro trabajo es posible gracias a los datos de muestra anonimizados que usuarios de todo el mundo comparten con nosotros voluntariamente. Estas “muestras de aprendizaje” (como se las conoce en la investigación de IA) se tratan siempre con el mayor respeto por la privacidad y la seguridad, y son un gran activo para la empresa, ya que nos ayudan a pulir y a optimizar nuestra tecnología.

Reconocimiento de escritura a mano: los desafíos
El reconocimiento de escritura a mano plantea importantes desafíos técnicos debido a la inmensa variedad de estilos de escritura y caligrafía. Factores como la edad de la persona que escribe, si es diestra o zurda, el país de origen e incluso la superficie de apoyo pueden afectar a la escritura, al margen de los efectos de los distintos idiomas y alfabetos.
Para ilustrar algunos de los retos: un buen software de reconocimiento de escritura a mano debe poder distinguir un carácter chino entre más de 30.000 ideogramas posibles. También debe ser capaz de reconocer y decodificar la escritura bidireccional, para continuar funcionando cuando alguien que usa un idioma de derecha a izquierda (como el árabe o el hebreo) incluye palabras extranjeras escritas de izquierda a derecha.
La escritura cursiva o con letra ligada hace que sea aún más difícil para el software segmentar y reconocer caracteres individuales, mientras que los trazos que se escriben con demora (como los signos diacríticos) suponen un riesgo de confusión mayor. Las disposiciones no estructuradas habituales en estas notas hacen que el análisis automatizado del contenido resulte mucho más complicado, al igual que la inclusión de otros contenidos como expresiones matemáticas, gráficos y tablas.
El tiempo también influye: el software de reconocimiento de escritura debe funcionar en tiempo real, interpretándolo todo mientras el usuario escribe. Si el usuario modifica el contenido mientras escribe, por ejemplo tachando una palabra para borrarla, insertando un espacio o moviendo un párrafo, el motor de reconocimiento debe ser capaz de no perder el hilo.
Además, la tecnología de reconocimiento debe poder analizar los caracteres de imprenta y no solo los trazos manuscritos, de forma que un usuario pueda importar texto desde páginas web u otras aplicaciones y añadir anotaciones a mano cuando sea necesario. Un buen motor de reconocimiento debe interpretar estas interacciones complejas con precisión, distinguiendo bien entre los gestos de edición, los signos diacríticos o la escritura de caracteres nuevos y palabras.
Invertir en redes neuronales
Hace más de 20 años, cuando la comunidad mundial de investigación del reconocimiento de escritura a mano centraba sus esfuerzos en los modelos ocultos de Markov (HMM) y las máquinas de vectores de soporte (SVM), MyScript optó por tomar otro camino.
Decidimos centrarnos en las redes neuronales.
Una red neuronal es un tipo de aprendizaje automático que imita los procesos de aprendizaje del cerebro humano. Impulsada por potentes algoritmos, una red neuronal identifica patrones en conjuntos enormes de datos, lo que permite generalizaciones más precisas sobre el objeto de estudio, como en nuestro caso la escritura a mano.
Las redes neuronales se construyen a partir de modelos matemáticos “entrenados” para identificar patrones o pautas de acuerdo con unas variables o “dimensiones” predeterminadas. Unos algoritmos cuidadosamente programados dividen y ordenan repetidamente los datos de acuerdo con estas dimensiones, clasificando y reclasificando hasta que surgen patrones claros.
De esta forma, las redes neuronales pueden realizar tareas que resultarían imposibles para los humanos. Criban ingentes cantidades de datos a gran velocidad, resaltando patrones que de otro modo podrían pasar inadvertidos. Teníamos la convicción de que podíamos usar las redes neuronales para entrenar el motor de reconocimiento de escritura a mano más preciso y avanzado jamás creado.
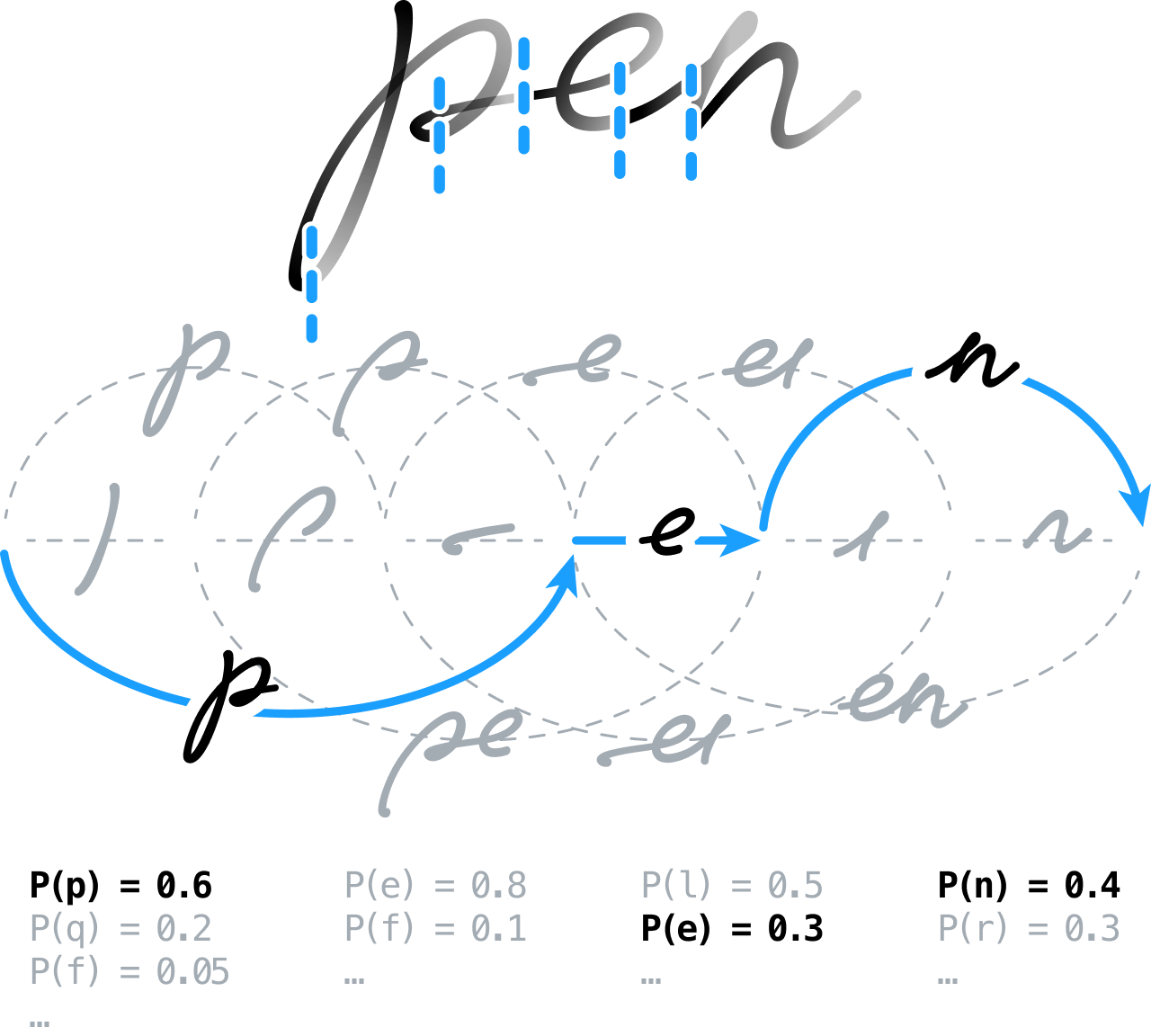
Uso de redes neuronales para reconocer la escritura a mano
Desde el principio, nuestra idea fue preprocesar el contenido manuscrito para prepararlo para el análisis, mediante tareas como extraer las líneas, normalizar la tinta o corregir las inclinaciones. Sobresegmentábamos entonces la señal y dejábamos que el motor de reconocimiento decidiera después la posición de los límites entre caracteres y palabras.
Esto implicaba construir un gráfico de segmentaciones mediante el modelado de todas las posibilidades, agrupando en la práctica segmentos contiguos en hipótesis de caracteres que luego se clasificaban por medio de redes neuronales prealimentadas. Seguimos un enfoque innovador basado en un esquema de entrenamiento global discriminatorio. Hoy en día, esta técnica se emplea con bastante frecuencia en el marco de la clasificación temporal conexionista (CTC), para entrenar sistemas neuronales secuencia a secuencia.
También construimos y empleamos un modelo de lenguaje estadístico de última generación con información léxica, gramatical y semántica que podía usarse para aclarar y resolver algunas de las ambigüedades que quedaran entre distintos caracteres candidatos.

Entrenamiento de IA para lenguajes 2D
Nuestro éxito con las redes neuronales nos permitió construir el mejor motor de reconocimiento de escritura a mano del mundo tanto para letra de imprenta como cursiva. Pero algunos idiomas ofrecen una complejidad aún mayor, lo que nos llevó al siguiente desafío.
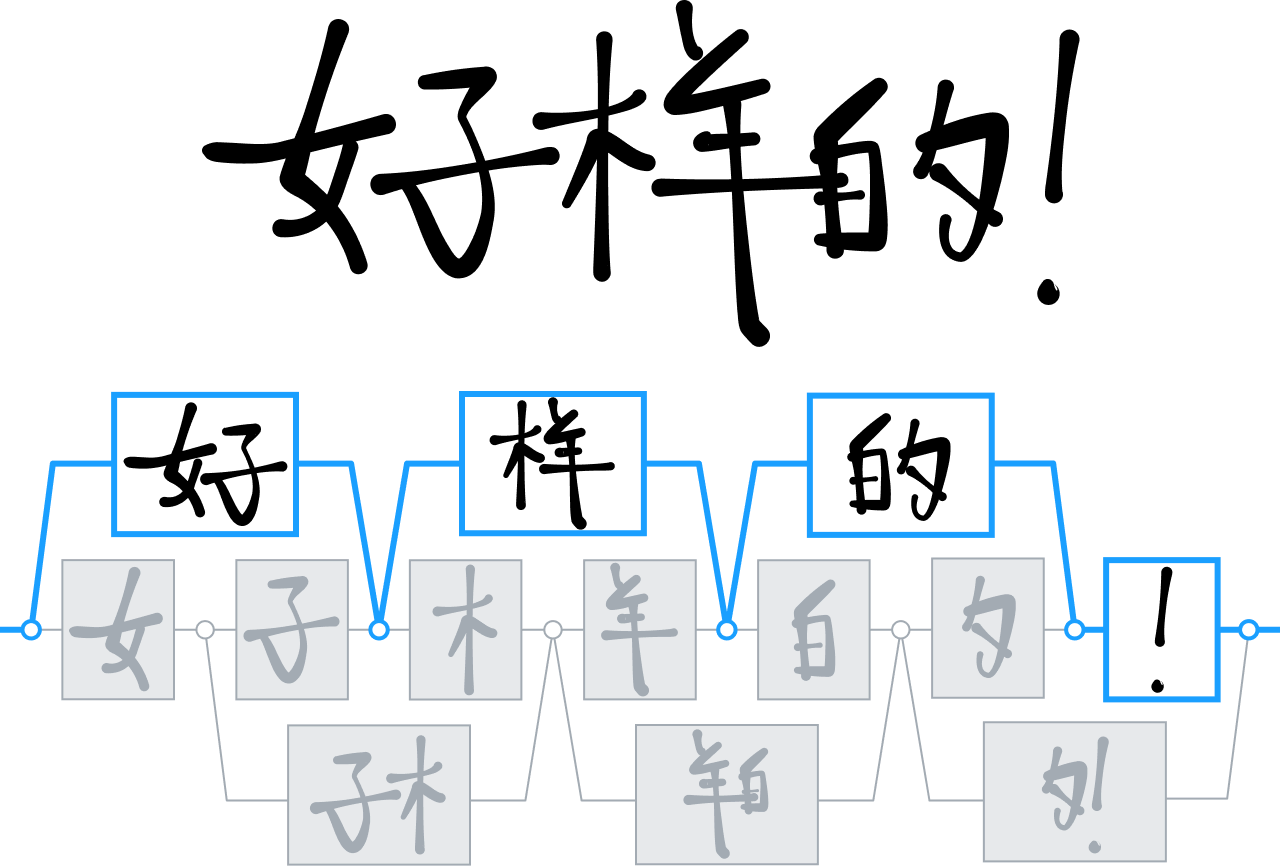
Reconocimiento de caracteres chinos
A lo largo de los años, MyScript ha desarrollado diversas tecnologías para analizar e interpretar lenguajes bidimensionales, entre ellos los ideogramas chinos.
Mientras que los competidores utilizaban mayoritariamente técnicas de árboles de decisión para diferenciar e interpretar los caracteres chinos, nosotros redoblamos la apuesta por las redes neuronales y entrenamos nuestro motor para que reconociera más de 30.000 ideogramas.
Era la primera vez que un equipo de investigación entrenaba con éxito una red tan extensa, algo que fue posible gracias a una campaña a gran escala de recopilación de datos cuyo resultado fue el conjunto de datos de caracteres chinos manuscritos más grande jamás visto.
Utilizamos estos datos para desarrollar una nueva arquitectura neuronal que explotara específicamente la estructura de los caracteres chinos; también integramos una técnica de agrupamiento especializada para acelerar los tiempos de procesamiento. Estas innovaciones nos permitieron ofrecer un nivel de reconocimiento de escritura a mano sin precedentes en un mercado en el que el uso del teclado sigue siendo dificultoso y poco flexible. También nos permitieron añadir el mismo nivel de compatibilidad con otros idiomas como el japonés, el hindi y el coreano.
Reconocimiento de cálculos matemáticos
Después de emplear con éxito las redes neuronales para analizar y reconocer idiomas de todo el mundo, se presentó un nuevo reto: el reconocimiento de expresiones matemáticas.
Mientras que los idiomas poseen secuencias estructurales de caracteres y palabras, los lenguajes bidimensionales (o visuales) a menudo se describen mejor con una estructura de árbol o gráfico, con relaciones espaciales entre los nodos. Al igual que con el texto, nuestro sistema de reconocimiento matemático se basa en el principio de que la segmentación, el reconocimiento y el análisis gramatical y semántico deben gestionarse simultáneamente y al mismo nivel, para producir los mejores candidatos de reconocimiento.
El sistema analiza las relaciones espaciales entre todas las partes de una ecuación matemática de acuerdo con las reglas establecidas en su gramática especializada, y a continuación utiliza este análisis para determinar la segmentación. La gramática en sí comprende un conjunto de reglas que describen cómo analizar una ecuación. Cada regla se asocia a una relación espacial concreta. Por ejemplo, una regla de fracción define una relación vertical entre un numerador, una barra de fracción y un denominador.
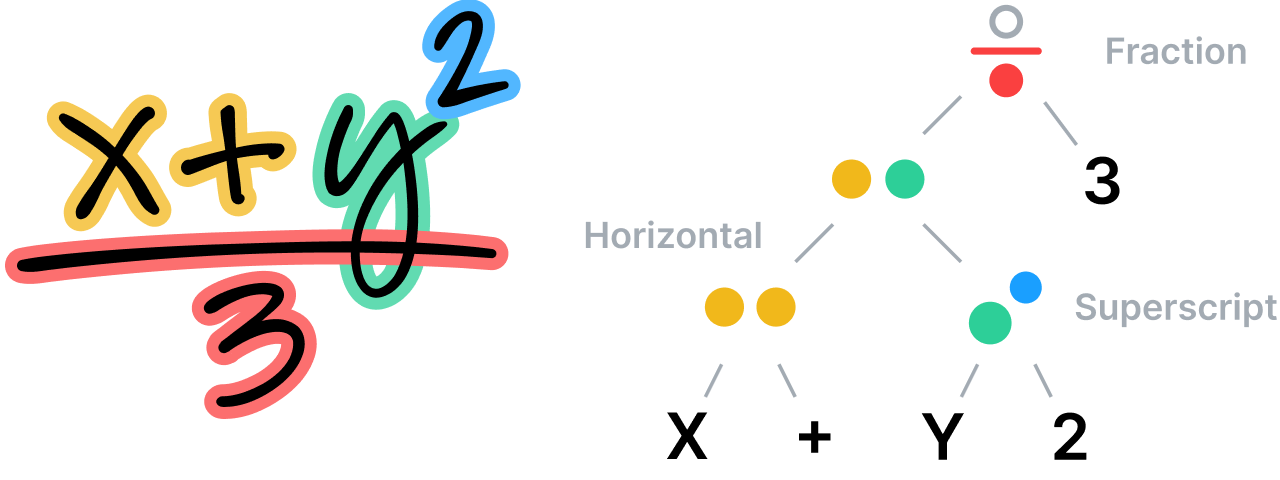
Comprensión de notas no estructuradas
El reconocimiento preciso e inmediato de las expresiones matemáticas abrió nuevas posibilidades relacionadas con la disposición y el contenido de las notas manuscritas.
Si nuestro motor de reconocimiento podía interpretar correctamente las relaciones espaciales entre las partes de una ecuación matemática, ¿podría identificar con precisión también otros tipos de contenido que no fueran texto? De ser así, podríamos comenzar a superar los problemas que plantean las notas no estructuradas, utilizando nuestra tecnología para identificar con precisión e incluso embellecer elementos como los diagramas dibujados a mano.
Pensamos que las arquitecturas de redes neuronales basadas en gráficos (GNN) eran adecuadas para esta tarea. La idea básica consiste en modelar un documento completo como gráfico, en el que los trazos están representados por nodos y conectados por aristas a los trazos vecinos.
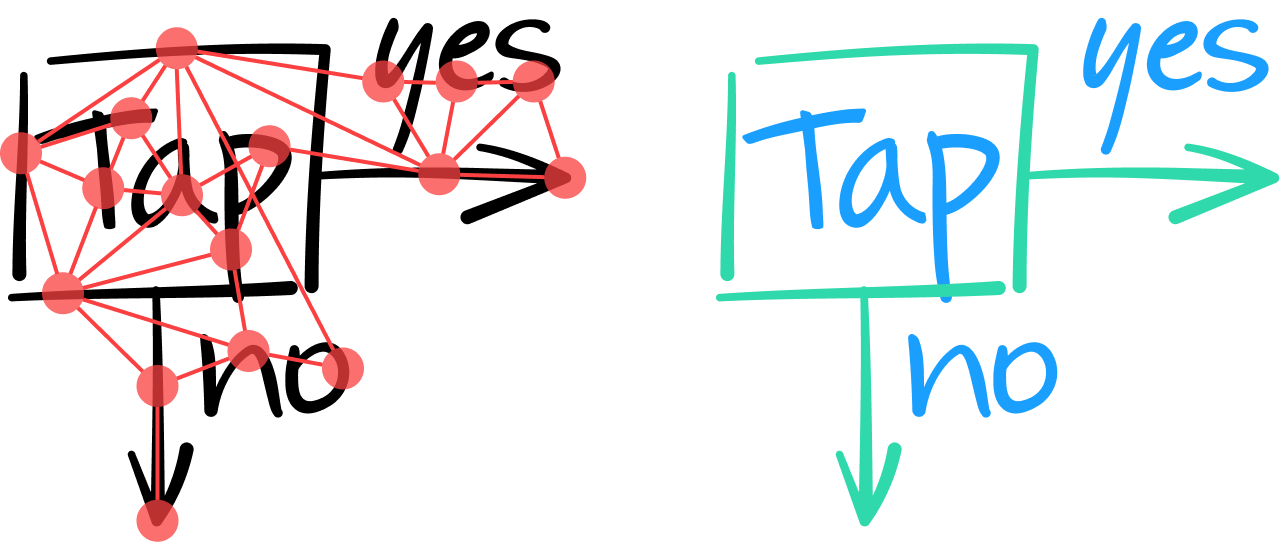
Al analizar así el contenido de una nota, la GNN debe clasificar todos los trazos como texto o como no texto. Esto se consigue analizando las características intrínsecas de cada trazo y, cuando es necesario, teniendo en cuenta la información contextual proporcionada por las aristas y los nodos vecinos de un trazo.
Una capa de la GNN combina las características de un nodo con las de sus vecinos para producir un vector de valores numéricos que representan características de nivel superior. Al igual que con las redes neuronales convolucionales, se pueden apilar varias capas para extraer un número mayor de características globales, lo que permite tomar una decisión más fundamentada sobre si un trazo es de texto o no. Por ejemplo, en el siguiente diagrama, las dos líneas verticales más a la izquierda son parecidas; solo mediante la integración de información contextual de los trazos vecinos, puede la GNN clasificar (en la capa de salida) que el trazo más a la izquierda es parte de una figura geométrica cuadrada, mientras que el de al lado es parte del carácter “T”.
Aprendizaje profundo y el modelo codificador-decodificador
No siempre es suficiente ofrecer los dos mejores sistemas para reconocer texto y operaciones matemáticas, especialmente para los usuarios que trabajan o estudian en campos científicos. Estos usuarios a menudo tienen que insertar cálculos matemáticos en mitad del texto (no en un espacio separado en la página) y esperan que el motor de reconocimiento interprete ambas cosas correctamente.
El desafío, pues, consistía en diseñar un sistema capaz de reconocer caracteres y palabras combinados con expresiones matemáticas. Es decir, analizar una combinación de un lenguaje natural unidimensional (texto) y un lenguaje bidimensional (matemáticas).
Con la corriente del aprendizaje profundo o “deep learning”, aparecieron nuevas arquitecturas de redes neuronales. Una de ellas, la de codificador-decodificador, ganó mucha popularidad para resolver problemas de conversión secuencia a secuencia. Puede gestionar entradas y salidas de longitud variable y se ha convertido en una referencia en ámbitos próximos al reconocimiento de la escritura a mano, como el reconocimiento de voz. La ventaja clave de un sistema codificador-decodificador es que todo el modelo se entrena de principio a fin, en lugar de entrenar cada elemento por separado. Se pueden emplear varias arquitecturas, incluidas las capas de redes neuronales convolucionales, las capas de redes neuronales recurrentes, las unidades LSTM (“Long Short-Term Memory”) y las capas de atención que se usan habitualmente en el modelo Transformer, por citar solo algunas.
En nuestro caso, la entrada del codificador-decodificador es una secuencia de coordenadas que representa la trayectoria de los trazos manuscritos con el lápiz. La salida es una secuencia de caracteres reconocidos en forma de símbolos LaTeX (por ejemplo, x^2 en vez de x², o (\frac{ }) en vez de una fracción).


El futuro de la escritura a mano con IA
A la evolución de la tecnología de reconocimiento de escritura aún le queda mucho camino por delante. Estamos trabajando ya en ampliar las capacidades de nuestra IA para que pueda resolver problemas como la identificación automática del idioma o las tablas manuscritas interactivas.
Creemos que los modelos de “deep learning” ofrecen un gran potencial de desarrollo y pueden permitirnos unificar nuestro enfoque en campos de investigación que antes no guardaban relación, como el procesamiento del lenguaje natural y el análisis de la disposición de los documentos. En combinación con la creciente ubicuidad de los dispositivos digitales con capacidades táctiles, estamos convencidos de que la IA nos permitirá pasar de “reconocer lo que vemos” a “reconocer lo que se pretendía hacer”. La diferencia puede parecer sutil en la página, pero en realidad representa un nuevo cambio de paradigma. Y es nuestro propósito contribuir a su consecución.
Nuestra visión de futuro es la de un mundo en el que cualquier persona pueda crear cualquier tipo de contenido en el dispositivo que elija con la misma libertad que tendría utilizando el papel, pero sin renunciar a un ápice de la potencia y la flexibilidad de lo digital. Gracias al poder de la inteligencia artificial, esa visión cada día está más cerca de hacerse realidad.
