Искусственный интеллект, нейронные сети и распознавание рукописного текста
Искусственный интеллект полностью меняет наши представления о том, как люди записывают информацию, и открывает новые горизонты для развития технологии цифрового рукописного ввода.
Важность искусственного интеллекта
Вместо полного термина «искусственный интеллект» часто используется аббревиатура «ИИ». Это направление информатики, где изучаются принципы создания интеллектуальных машин, способных воспроизводить и дополнять определенные функции человеческого мозга, в частности навыки чтения, понимания или анализа.
Искусственный интеллект в MyScript
В основе наших главных программных продуктов лежит модуль ИИ собственной разработки. Искусственный интеллект помогает нам распознавать рукописное содержимое на более чем 70 языках, анализировать структуру рукописных заметок, понимать математические уравнения и даже определять и преобразовывать записанные от руки ноты.
Мы развиваем и совершенствуем эту технологию уже более 20 лет. Стремясь создать самый точный в мире модуль распознавания рукописного текста, мы провели (и продолжаем проводить) множество исследований, посвященных языковым нюансам: построение предложений от уровня слова и слов от уровня символа, правила размещения диакритических знаков над определенными гласными или под ними и т. д.
Несколько групп исследователей MyScript непрерывно работают над оптимизацией лучшей в своем классе системы, способной распознавать впечатляющий массив рукописного содержимого.
Исследования по рукописному вводу текста
Наши специалисты из отдела исследований по рукописному вводу текста занимаются решением проблем с преобразованием последовательностей (seq2seq) — например, преобразование рукописного текста в составляющие его символы — при помощи технологий машинного обучения.
Их необходимо адаптировать с учетом алфавитов мира и конвенций. Это обязательное условие для распознавания, например, языков с написанием справа налево, в частности арабского и иврита, диакритических гласных в индийских текстах, китайских иероглифов, корейского алфавита Хангыль либо вертикальных символов из японских азбук хирагана, катакана и кандзи.
Исследования по рукописному вводу двумерного текста
Этот отдел отвечает за построение математических моделей на основе синтаксических анализаторов двумерных массивов и/или грамматических правил. Они занимаются теми проблемами, которые невозможно решить методом преобразования последовательностей. Это распознавание математических выражений, нот или диаграмм и графиков. Эти специалисты применяют для распознавания методы на основе графиков. Основной сложностью является обработка данных в режиме реального времени.
Исследования по обработке текстов на естественном языке
Наши специалисты по обработке текстов на естественном языке создают алгоритмы, умеющие воспринимать языки так же естественно, как человек. Это подразделение работает с корпусом текстов, где содержатся сотни миллионов слов из общедоступных документов и статей. Из них составляются словари, на их основе разрабатываются модели для подставления символов в предложениях и системы для обнаружения и исправления опечаток.
Сбор данных
Немалая часть нашей работы строится на обработке анонимных образцов данных, которые добровольно присылают нам пользователи из разных стран мира. В отношении этих «обучающих примеров» (так их называют исследователи искусственного интеллекта) всегда применяются самые строгие стандарты конфиденциальности и защиты. Это очень ценная для компании информация, которая позволяет нам совершенствовать и расширять возможности технологии.

Распознавание рукописного текста: сложности
Распознавание рукописного текста неразрывно связано с серьезными техническими сложностями из-за огромной вариативности почерков. На результат могут повлиять возраст автора, ведущая рука, родная страна, даже поверхность, на которой он пишет, — и все это без учета влияния языка и алфавита.
Чтобы проиллюстрировать это наглядно, приведем пример: эффективное ПО для распознавания рукописного текста должно уметь выделить нужный китайский иероглиф среди более 30 000 возможных вариаций. Ожидается также, что оно будет поддерживать функции распознавания и расшифровки двунаправленного письма, чтобы исключить сбои, когда в языке с написанием справа налево (например, арабский или иврит) встречаются иностранные слова с написанием слева направо.
Почерк со слитным написанием еще больше усложняет задачи по сегментации и распознаванию отдельных символов, а задержки при добавлении штрихов (в частности диакритических знаков) вносят дополнительную путаницу. Характерное для них отсутствие четкой структуры делает автоматический анализ содержимого еще более трудоемким. Не упрощает его и наличие объектов из других категорий: математических выражений, графиков и таблиц.
Важен также фактор времени: ПО для распознавания рукописного текста должно анализировать вводимые пользователем данные в режиме реального времени, по мере написания. Если пользователь вносит правки, например зачеркивает слово, чтобы удалить его, вставляет пробел или перемещает абзац, то модуль распознавания должен отреагировать своевременно.
Помимо прочего, от решения по распознаванию рукописного текста требуется умение анализировать как печатные символы, так и рукописные штрихи, чтобы пользователи могли импортировать напечатанный текст с веб-страниц или из других приложений, а затем аннотировать его от руки, если потребуется. Надежный модуль распознавания должен обрабатывать такие сложные взаимодействия с высокой точностью, безошибочно различая жесты редактирования, добавления диакритических знаков и написания новых символов и слов.
Инвестиции в развитие нейронных сетей
Более 20 лет назад, когда международное сообщество по изучению принципов распознавания рукописного текста активно исследовало скрытые марковские модели и методы опорных векторов, компания MyScript выбрала другой путь.
Мы решили сосредоточиться на нейронных сетях.
Нейронная сеть — это метод машинного обучения, копирующий процессы познания, которые протекают в мозге человека. Мощные алгоритмы в основе нейронной сети позволяют выявлять шаблоны в больших наборах данных, повышая точность обобщений в изучаемой области — в нашем случае это рукописный ввод текста.
Нейронные сети состоят из математических моделей, которые «учатся» находить шаблоны при помощи заранее заданных переменных («критерии»). Тщательно запрограммированные алгоритмы постоянно разделяют и сортируют данные на основании указанных критериев, снова и снова классифицируя их до обнаружения четких шаблонов.
Это значит, что нейронным сетям под силу задачи, с которыми не сможет справиться человек. Они с высокой скоростью «просеивают» огромные объемы информации, позволяя регистрировать шаблоны, во всех других случаях ускользнувшие бы от внимания. Мы были уверены, что сумеем при помощи нейронных сетей обучить наш модуль распознавания рукописного текста для получения самой точной и передовой технологии в мире.
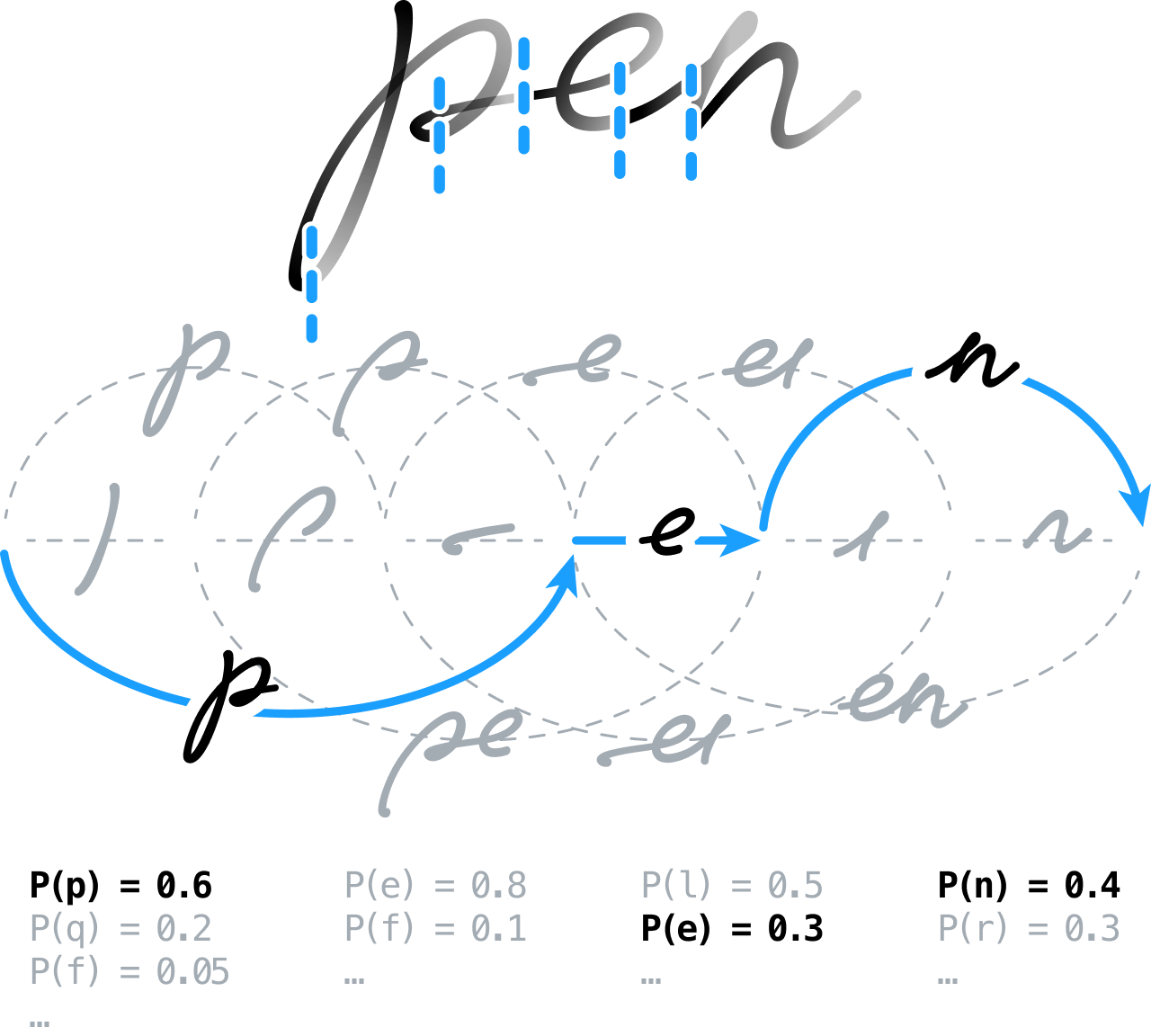
Распознавание рукописного текста при помощи нейронных сетей
Изначально идея заключалась в предварительной обработке рукописного содержимого для подготовки к анализу: извлечение строк, выравнивание тона чернил и исправление наклоненных символов. Затем предполагалось выполнять сверхсегментацию и пропускать текст через модуль распознавания для обнаружения границ между символами и словами.
Это подразумевало построение графика сегментации путем моделирования всех существующих вариантов: в сущности, группировка смежных сегментов в предполагаемые комбинации символов, которые бы после этого классифицировались при помощи нейронных сетей прямого распространения. Мы выбрали инновационный подход, основанный на схеме глобального дифференцированного обучения. Сегодня эту методику часто применяют в рамках коннекционной временной классификации (CTC) для обучения нейронных систем по преобразованию последовательностей.
Мы также совершили небольшую революцию, создав и внедрив статистическую языковую модель, объединявшую в себе лексические, грамматические и семантические данные. Она сделала возможным уточнение результатов и устранение части противоречий при наличии нескольких подходящих символов.

Обучение искусственного интеллекта для двумерных языков
Использование нейронных сетей принесло нам успех и позволило создать лучший в мире модуль распознавания, поддерживающий работу и с печатными, и с рукописными символами. Но некоторые языки оказались намного более сложными по структуре, в результате чего перед нами возникла новая сложность.
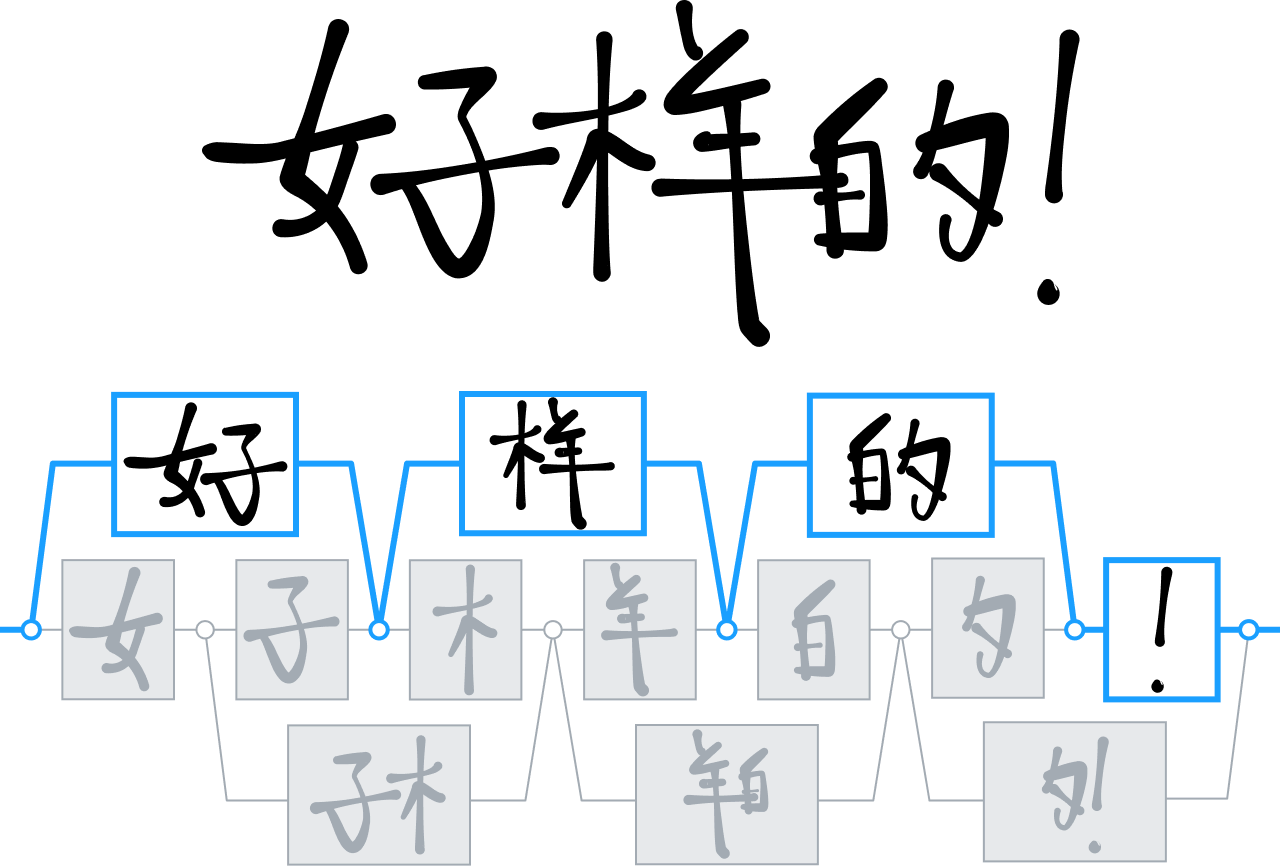
Распознавание китайских символов
За время своего существования компания MyScript создала целый ряд технических решений по анализу и распознаванию двумерных языков, особенно китайских иероглифов.
Когда большинство наших конкурентов пошло по пути анализа и распознавания китайских символов при помощи моделей в виде деревьев решений, мы сконцентрировали все усилия на совершенствовании нейронных сетей, обучая наш модуль так, чтобы он мог узнать любой из более чем 30 000 иероглифов.
Впервые в истории отрасли исследовательскому подразделению удалось успешно подготовить к работе настолько крупную сеть. Это стало возможным благодаря масштабной кампании по сбору данных, позволившей нам накопить крупнейший массив текстов с рукописными символами на китайском языке.
На основе этих данных была выстроена новая нейронная архитектура, где учитывались все особенности написания китайских иероглифов. Кроме того, мы добавили специальный механизм кластеризации, чтобы обработка происходила быстрее. Эти инновационные методики помогли нам выйти на новый уровень распознавания рукописных текстов в сегменте, где ввод данных с клавиатуры остается чрезмерно сложной и негибкой процедурой. Кроме того, за счет этого удалось обеспечить аналогичный уровень поддержки для других языков, в том числе японского, хинди и корейского.
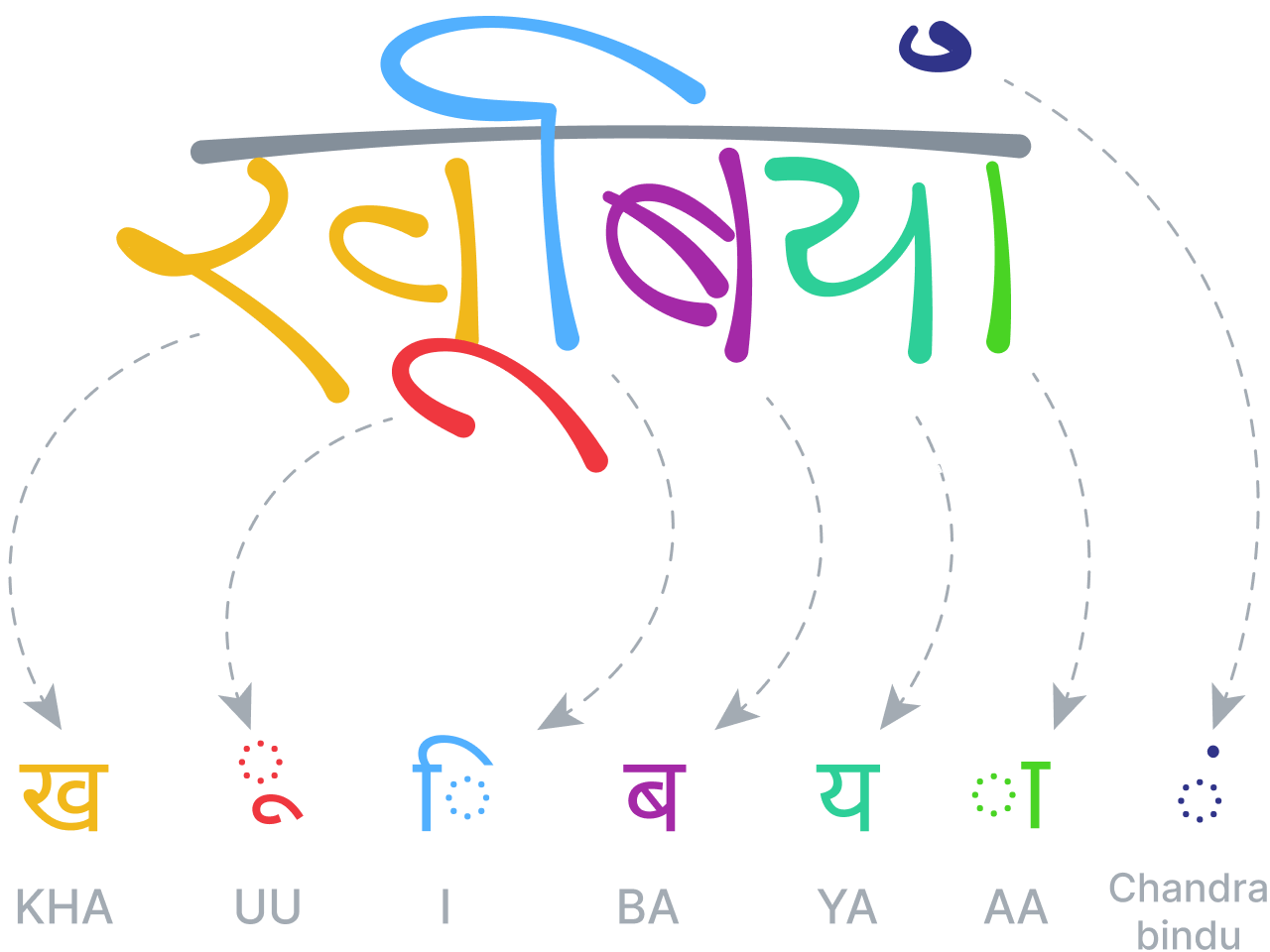
Распознавание математических выражений
Когда нейронные сети научились успешно анализировать и распознавать тексты на самых разных языках мира, мы поставили перед собой новую цель: познакомить наш модуль с математическими выражениями.
Если в регулярных языках символы и слова объединяются в структурные последовательности, то в двумерных языках (с визуальным синтаксисом) преобладает структура дерева или графа с пространственными отношениями между узлами. Как и в случае с текстами, наша система распознавания математических выражений строится на том принципе, что для получения самых точных результатов процессы сегментации, распознавания и грамматико-синтаксического анализа должны протекать одновременно и на одном уровне.
Наш модуль определяет пространственные отношения между частями математического уравнения по правилам, на которых основывается его особая грамматическая структура, а затем использует эти данные для разбивки выражения на сегменты. Грамматическая структура сама по себе представляет набор правил, описывающих принципы анализа уравнения. Каждому правилу соответствует конкретное пространственное отношение. Например, правило дроби определяет вертикальные взаимоотношения между числителем, дробной чертой и знаменателем.
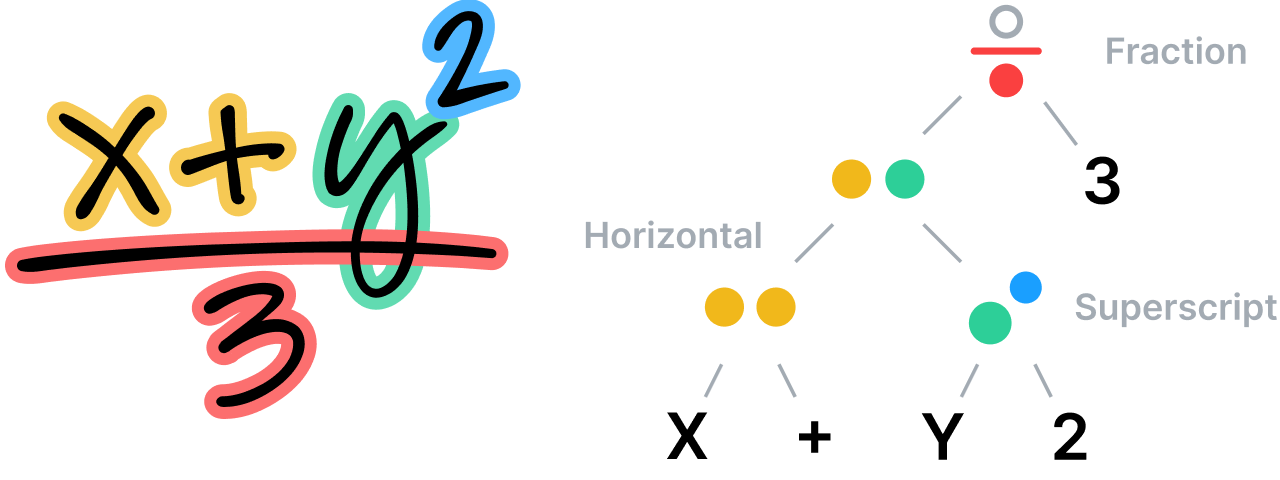
Понимание неупорядоченных заметок
Возможность быстро и точно распознавать математические выражения открыла совершенно новые возможности для работы со структурой и содержимым рукописных заметок.
Если модуль распознавания способен правильно определять пространственные отношения между частями математических уравнений, может ли он так же точно классифицировать нетекстовые объекты? Если да, то это позволило бы справиться с проблемами обработки неупорядоченных заметок, используя нашу технологию для точного определения элементов и даже улучшения вида некоторых из них, например нарисованных от руки диаграмм.
Мы посчитали, что для этих целей лучше всего подойдут графовые нейронные сети (GNN). В данном случае основной идеей является представление всего документа в виде графа, где штрихи представлены узлами и соединены с соседними штрихами при помощи ребер.
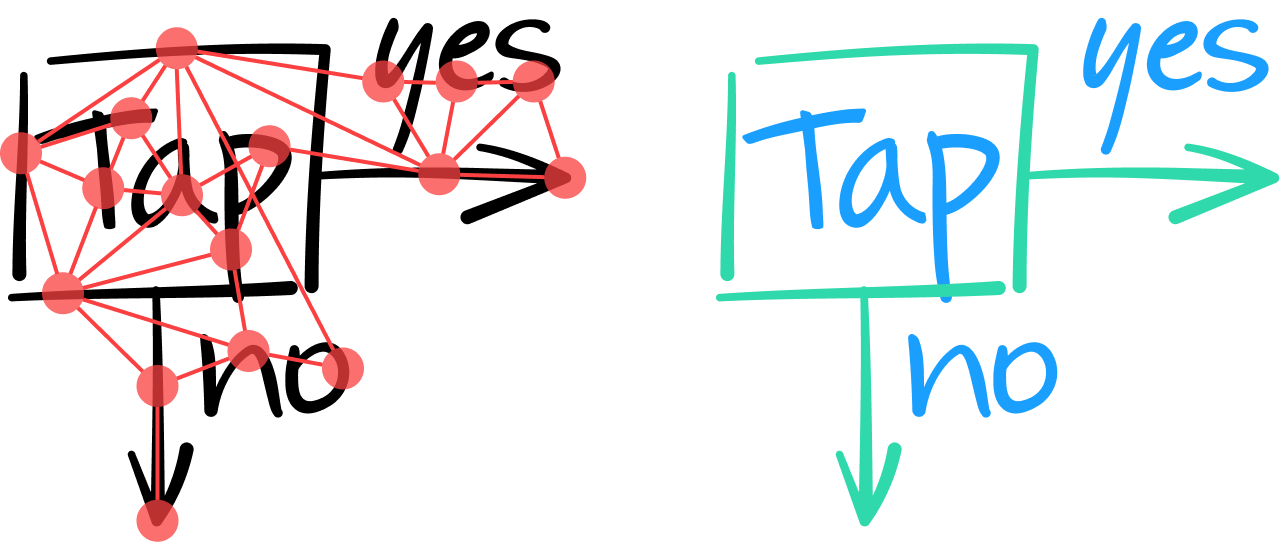
При анализе содержимого заметки таким способом графовая нейронная сеть должна классифицировать каждый штрих как текстовый или нетекстовый символ. Для этого проверяются собственные характеристики каждого штриха и (если необходимо) контекстные данные, полученные от его соседних ребер и узлов.
Один из уровней в графовой нейронной сети объединяет все характеристики узла с характеристиками соседних объектов и формирует вектор числовых значений, представляющих характеристики более высокого уровня. Как и в сверточных нейронных сетях, поддерживается объединение нескольких уровней в стек для получения большего числа глобальных характеристик и, соответственно, более точного отнесения штрихов к текстовым или нетекстовым. На схеме ниже, например, 2 вертикальные линии слева кажутся одинаковыми. И только после получения контекстных данных от соседних штрихов графовая нейронная сеть может на уровне вывода классифицировать их как часть прямоугольника (крайняя левая черта) и часть символа T.
Глубокое обучение и модель кодирования/декодирования
Пары лучших в своем классе систем для распознавания текста и математических выражений тоже может оказаться недостаточно — особенно для пользователей, работающих или обучающихся для работы в определенной сфере науки. Им часто нужно записывать математические формулы прямо во время ввода текста (не в специально выделенном пространстве на странице), и они рассчитывают, что модуль распознавания сможет обработать их правильно.
Сложность заключалась в том, чтобы создать систему, которая могла бы распознавать символы и слова наряду с математическими выражениями, то есть анализировать сочетания символов из естественного одномерного языка (текст) и двумерного языка (математические формулы).
С появлением технологии глубокого обучения пришли новые архитектуры нейронных сетей. Одна из них, модель кодирования/декодирования, стала очень популярным средством решения проблем с преобразованием последовательностей. Она позволяет обрабатывать вводимые и выводимые строки переменной длины, поэтому быстро приобрела популярность в сферах, как-либо связанных с распознаванием рукописного текста (например, распознавание речи). Главным преимуществом технологии кодирования/декодирования является комплексное обучение, в отличие от систем, где каждый элемент необходимо обучать отдельно. Поддерживается внедрение нескольких архитектур, в том числе сверточных нейронных сетей, рекуррентных нейронных сетей, сетей с долгой краткосрочной памятью (LSTM) и сетей на основе механизма внимания, обычно используемых в модели Transformer (среди множества прочих).
В нашем случае модель кодирования/декодирования получает данные в виде последовательности координат, где отражена траектория рукописных штрихов. Массивом выходных данных здесь является последовательность распознанных символов в формате LaTeX (например, x^2 вместо x² или (\frac{ }) вместо дроби).


Будущее рукописного ввода на основе искусственного интеллекта
Эволюция технологий распознавания рукописного текста еще даже не приблизилась к финальной стадии. Мы уже расширяем возможности ИИ для решения таких задач, как автоматическое определение языка и распознавание интерактивных рукописных таблиц.
Мы убеждены, что модели глубокого обучения имеют огромный потенциал развития. Возможно, они помогут нам унифицировать подход в тех сферах исследования, которые раньше не считались смежными (например, обработка текстов на естественном языке и анализ структуры). Принимая во внимание исключительную доступность цифровых устройств с поддержкой сенсорного ввода, мы уверены, что алгоритмы искусственного интеллекта помогут нам перейти от распознавания увиденного к распознаванию намерения. При анализе уже написанного содержимого разница может казаться минимальной, но в действительности это станет новой парадигмой. И мы готовы помочь взять этот барьер.
Нам хотелось бы, чтобы каждый в этом мире мог создавать любое содержимое на привычном ему устройстве будто бы на листе бумаги, но со всеми возможностями и максимальной гибкостью цифрового формата. Благодаря потенциалу искусственного интеллекта эта концепция с каждым днем все ближе к своему воплощению.
