L'importanza dell'IA
IA sta per "intelligenza artificiale". Si riferisce al campo dell'informatica che si occupa della creazione di macchine intelligenti capaci di riprodurre e migliorare certe capacità del cervello umano, come la lettura, la comprensione o l'analisi.
IA in MyScript
I nostri principali prodotti software sono basati su tecnologia IA proprietaria. Usiamo l'IA per interpretare contenuti scritti a mano in più di 70 lingue, analizzare la struttura delle note, capire le equazioni matematiche e persino per riconoscere e convertire la notazione musicale fatta a mano.
La nostra tecnologia ha alle spalle oltre 20 anni di ricerca e sviluppo. Per creare il motore di riconoscimento della scrittura a mano più preciso al mondo, abbiamo condotto (e continuiamo a condurre) ricerche sui dettagli della formazione del linguaggio: come si costruiscono le frasi dalle parole e le parole dai caratteri; come si collocano i segni diacritici sopra o sotto certe vocali e così via.
In MyScript, diversi gruppi di ricercatori stanno collaborando per ideare e sviluppare un sistema all'avanguardia in grado di comprendere una vasta gamma di contenuti scritti a mano.
Ricerca sul testo scritto a mano
Il nostro team di ricerca sul testo scritto a mano usa tecniche di apprendimento automatico per risolvere problemi che possono essere formulati come problemi di conversione sequence-to-sequence (o seq2seq), come quando si converte un testo scritto a mano nei suoi caratteri costitutivi.
Le tecniche devono essere adattate a diversi alfabeti e convenzioni per permettere il riconoscimento, ad esempio, delle lingue che si scrivono da destra a sinistra come l'arabo o l'ebraico, gli ideogrammi cinesi, l'alfabeto coreano hangul o i caratteri hiragana, katakana, kanji del giapponese scritti in verticale.
Ricerca sulla scrittura a mano in 2D
Questo team costruisce modelli matematici basati su grammatiche e/o parser bidimensionali. Si occupa di problemi che non possono essere risolti da approcci seq2seq, come il riconoscimento di espressioni matematiche, la notazione musicale o diagrammi e schemi. Usa tecniche basate su grafici per permettere il riconoscimento. L'elaborazione in tempo reale costituisce una grande sfida.
Ricerca sull'elaborazione del linguaggio naturale
Il nostro team di elaborazione del linguaggio naturale (NLP) sviluppa algoritmi capaci di comprendere le lingue con la stessa naturalezza di un essere umano. Il team utilizza corpora testuali contenenti centinaia di milioni di parole tratte da documenti e articoli disponibili pubblicamente. Da lì, costruisce vocabolari linguistici, elabora modelli per prevedere il prossimo carattere in una frase e progetta sistemi che identificano e correggono gli errori di ortografia.
Raccolta di dati
Gran parte del nostro lavoro è reso possibile dai dati campione anonimizzati che gli utenti di tutto il mondo condividono volontariamente con noi. Questi campioni per l'addestramento (o "training samples", come li conosce la ricerca IA) sono sempre trattati con il massimo rispetto per la privacy e la sicurezza, e sono una grande risorsa per l'azienda in quanto ci aiutano a perfezionare e ottimizzare la nostra tecnologia.
Riconoscimento della scrittura a mano: le sfide
Il riconoscimento della scrittura a mano pone sfide tecniche significative a causa dell'immensa varietà di stili di scrittura e calligrafia. Fattori come l'età di chi scrive, se la persona è destra o mancina, il paese d'origine e persino la superficie d'appoggio possono influenzare la scrittura, oltre agli effetti delle diverse lingue e alfabeti.
Per illustrare alcune delle sfide: un buon software di riconoscimento della scrittura a mano deve riuscire a distinguere un carattere cinese da più di 30.000 ideogrammi possibili. Deve anche essere in grado di riconoscere la scrittura bidirezionale, per identificare quando un utente che scrive naturalmente da destra a sinistra (in lingue come l'arabo o l'ebraico) include parole straniere scritte da sinistra a destra.
La scrittura corsiva rende ancora più difficile per il software segmentare e riconoscere i singoli caratteri, mentre i tratti che sono scritti con un ritardo (come i segni diacritici) comportano un maggior rischio di confusione. I layout non strutturati, comuni in queste note, rendono l'analisi automatizzata del contenuto molto più complicata, così come l'inclusione di altri tipi di contenuto quali espressioni matematiche, grafici e tabelle.
Anche il tempo di elaborazione è un fattore importante: il software di riconoscimento della scrittura deve funzionare in tempo reale, interpretando tutto mentre l'utente scrive. Se l'utente modifica il contenuto mentre scrive, ad esempio barrando una parola per cancellarla, inserendo uno spazio o spostando un paragrafo, il motore di riconoscimento deve essere in grado di non perdere il filo.
Inoltre, la tecnologia di riconoscimento deve riuscire ad analizzare i caratteri di stampa così come i tratti scritti a mano, in modo che un utente possa importare testo da pagine web o altre applicazioni e aggiungere annotazioni a mano, se vuole. Il motore di riconoscimento deve interpretare queste interazioni complesse con precisione, distinguendo i gesti di modifica, i segni diacritici o la scrittura di nuovi caratteri e parole.
Investire sulle reti neurali
Più di 20 anni fa, quando la comunità mondiale di ricerca sul riconoscimento della scrittura a mano stava concentrando i suoi sforzi sui modelli di Markov nascosti (HMM) e sulle macchine a vettori di supporto (SVM), MyScript ha scelto di prendere un'altra strada.
Ci siamo concentrati sulle reti neurali.
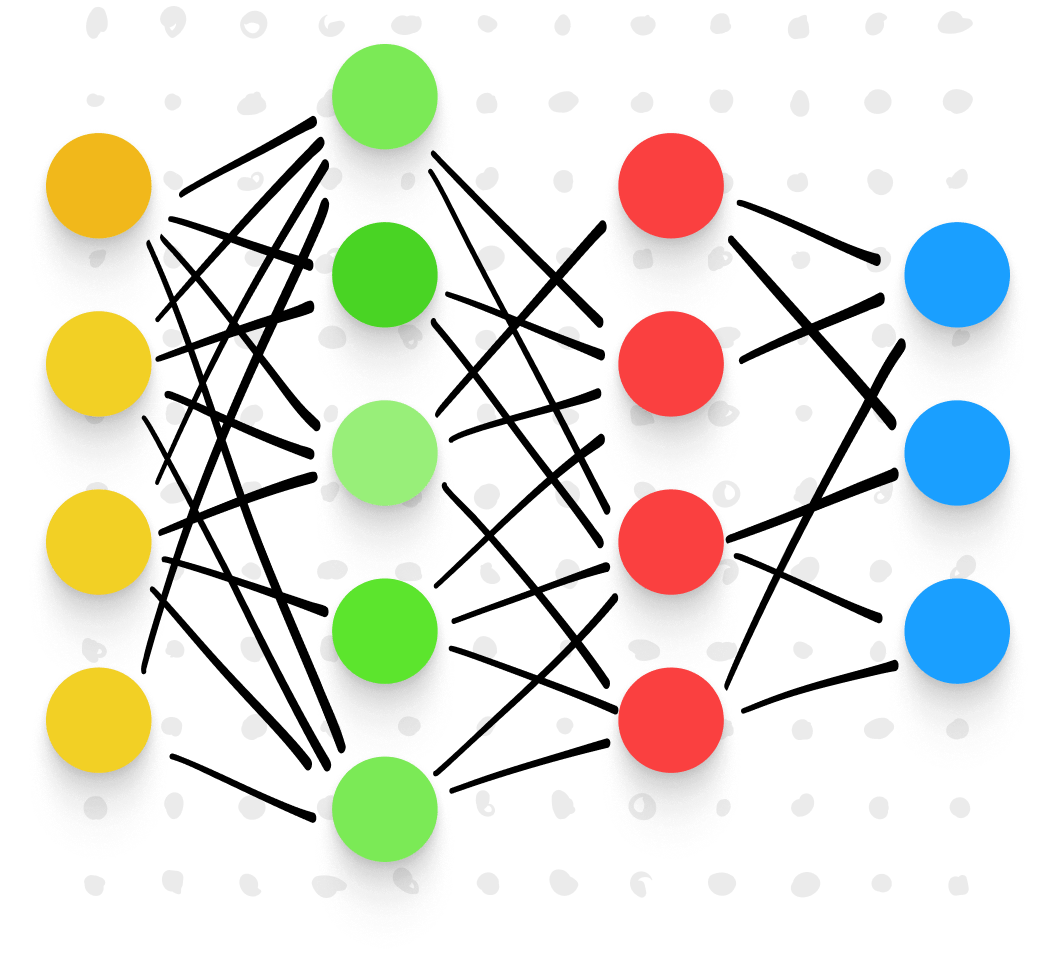
Una rete neurale è un tipo di machine learning che imita i processi di apprendimento del cervello umano. Alimentata da potenti algoritmi, una rete neurale identifica i pattern in enormi set di dati, permettendo generalizzazioni più precise sull'oggetto di studio, come nel nostro caso la scrittura a mano.
Le reti neurali sono costruite a partire da modelli matematici "addestrati" per identificare pattern o schemi secondo variabili o "dimensioni" predeterminate. Algoritmi attentamente programmati dividono e ordinano ripetutamente i dati in base a queste dimensioni, classificando e riclassificando finché non emergono pattern chiari.
In questo modo, le reti neurali possono eseguire compiti che sarebbero impossibili per gli esseri umani. Passano al setaccio enormi quantità di dati ad alta velocità, evidenziando pattern che altrimenti potrebbero passare inosservati. Eravamo convinti di poter utilizzare le reti neurali per addestrare il motore di riconoscimento della scrittura a mano più preciso e avanzato mai creato.
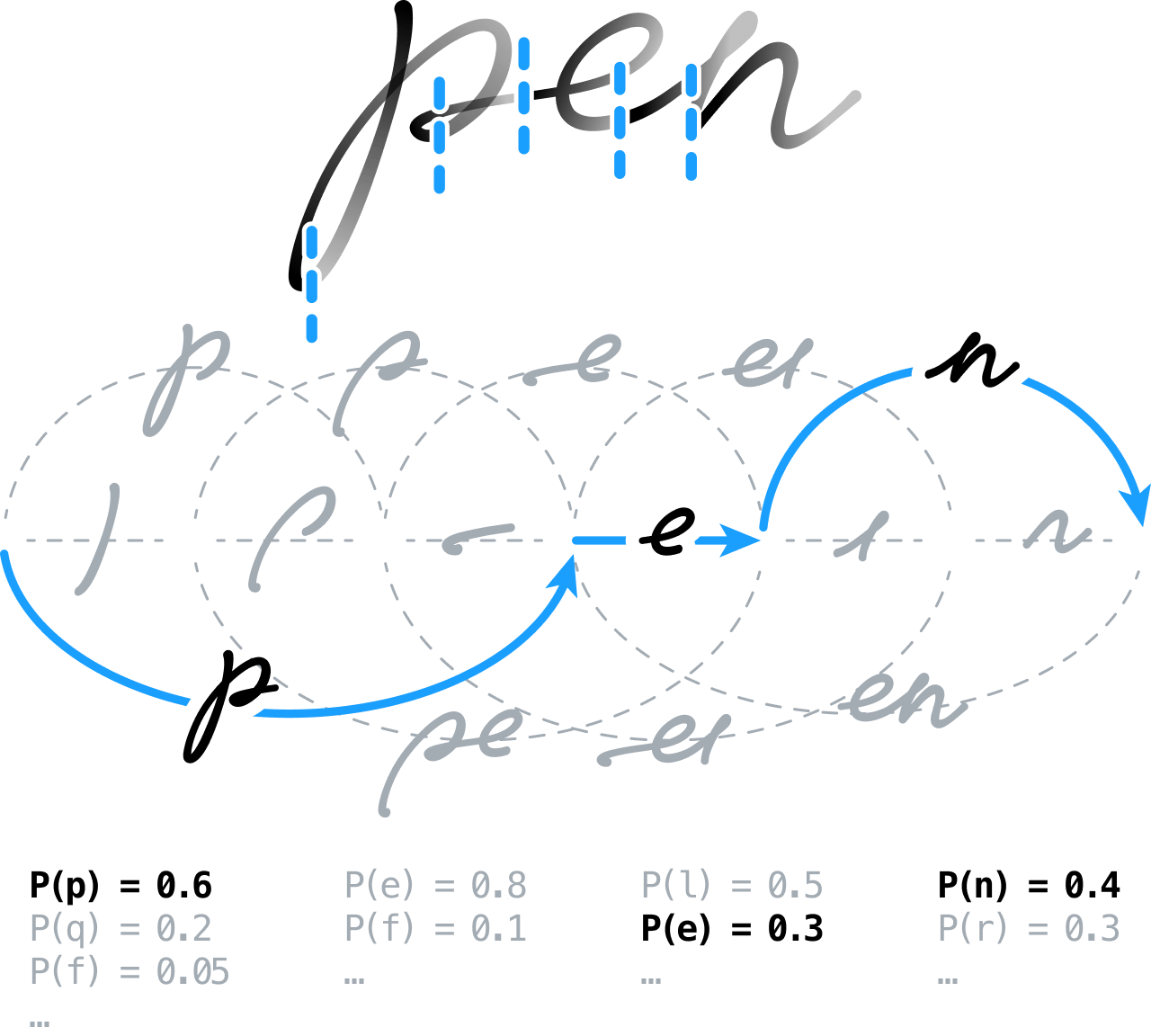
Usare le reti neurali per riconoscere la scrittura a mano
La nostra idea iniziale era quella di pre-processare il contenuto scritto a mano per prepararlo all'analisi, eseguendo operazioni come l'estrazione delle linee, la normalizzazione dell'inchiostro e la correzione delle inclinazioni della scrittura. Poi avremmo sotto-segmentato il segnale e lasciato che il motore di riconoscimento decidesse la posizione dei confini tra i caratteri e le parole.
Si trattava di costruire un grafico di segmentazioni attraverso i modelli di tutte le possibilità, raggruppando in pratica i segmenti contigui in ipotesi di caratteri che venivano poi classificate per mezzo di reti neurali feed-forward. Abbiamo seguito un approccio innovativo basato su uno schema di addestramento globale discriminante. Oggi, questa tecnica è spesso impiegata nel quadro della classificazione temporale connessionista (CTC), per addestrare sistemi neurali sequence-to-sequence.
Abbiamo anche costruito e utilizzato un modello linguistico statistico all'avanguardia con informazioni lessicali, grammaticali e semantiche che potrebbero essere utilizzate per chiarire e risolvere alcune delle ultime ambiguità tra le diverse interpretazioni di caratteri.
Addestrare l'IA per le lingue 2D
Il nostro successo con le reti neurali ci ha permesso di costruire il miglior motore di riconoscimento della scrittura stampata e corsiva. Ma alcune lingue sono ancora più complesse, il che ci ha portato alla sfida successiva.
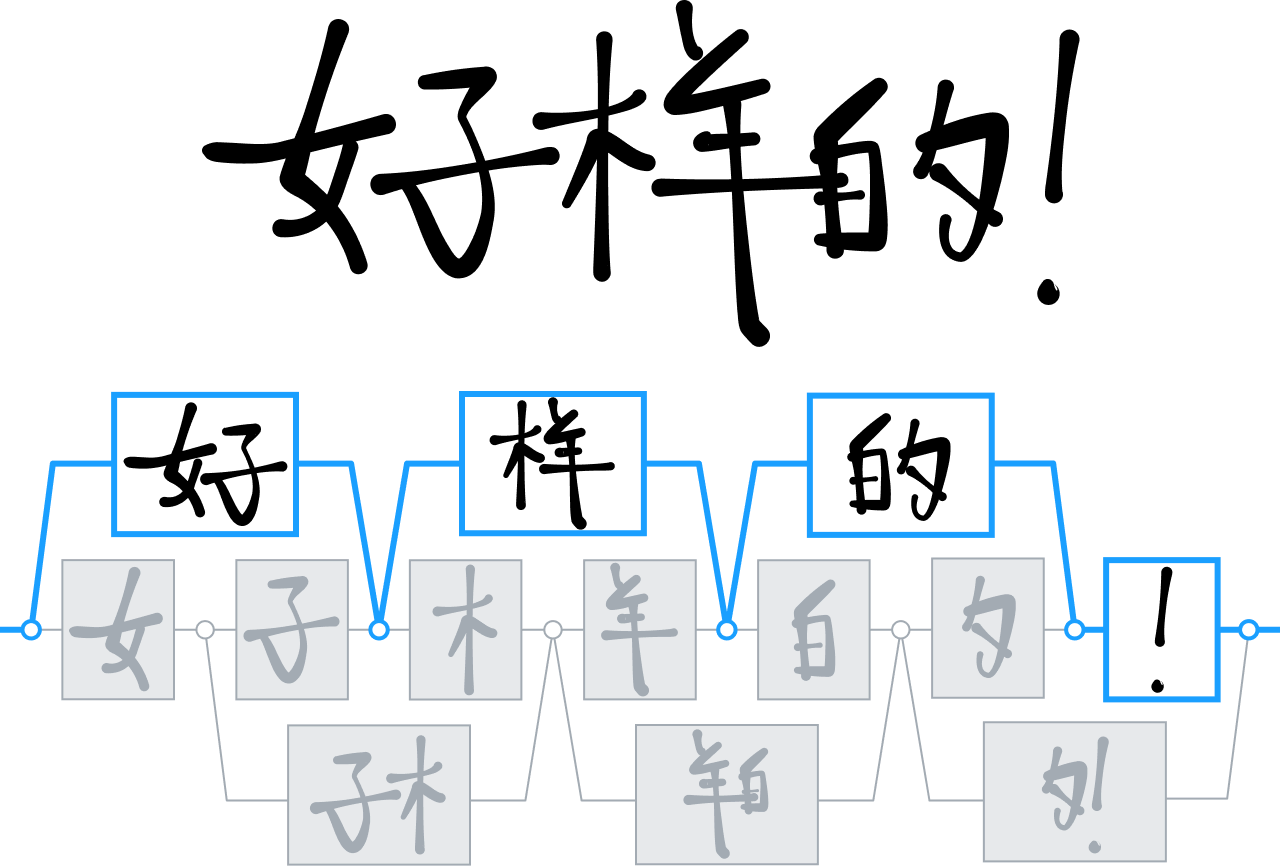
Riconoscimento dei caratteri cinesi
Nel corso degli anni, MyScript ha sviluppato varie tecnologie per analizzare e interpretare le lingue bidimensionali, compreso il riconoscimento degli ideogrammi cinesi.
Mentre gran parte della concorrenza usava per lo più tecniche ad albero di decisione per differenziare e interpretare i caratteri cinesi, noi abbiamo raddoppiato la posta in gioco sulle reti neurali addestrando il nostro motore a riconoscere più di 30.000 ideogrammi.
Era la prima volta che un team di ricerca addestrava con successo una rete così estesa, grazie a una campagna di raccolta dati su larga scala che aveva portato al più grande dataset di caratteri cinesi scritti a mano mai visto.
Abbiamo usato quei dati per sviluppare una nuova architettura neurale che sfrutta specificamente la struttura dei caratteri cinesi, nonché integrato una tecnica specializzata di clustering per accelerare i tempi di elaborazione. In un mercato dove l'uso della tastiera rimane scomodo e poco flessibile, queste innovazioni ci hanno permesso di offrire un livello di riconoscimento della scrittura a mano senza precedenti. Livello che abbiamo raggiunto anche per altre lingue come il giapponese, l'hindi e il coreano.
Riconoscimento della matematica
Dopo aver utilizzato con successo le reti neurali per analizzare e riconoscere lingue di tutto il mondo, si è presentata una nuova sfida: il riconoscimento delle espressioni matematiche.
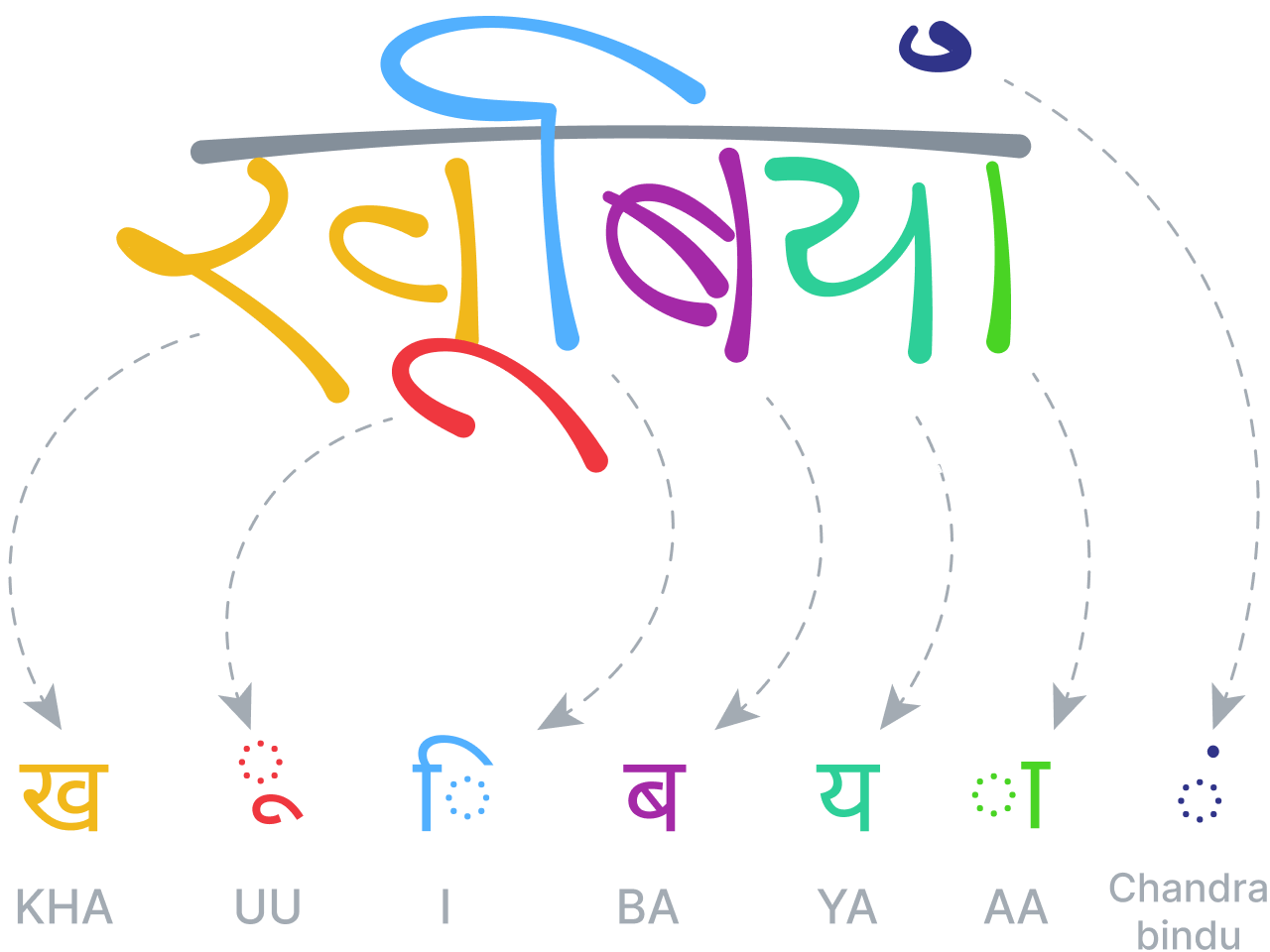
Dove le lingue standard hanno sequenze strutturali di caratteri e parole, le lingue bidimensionali (o visive) sono spesso meglio descritte da una struttura ad albero o grafico, con relazioni spaziali tra i nodi. Come per il testo, il nostro sistema di riconoscimento matematico si basa sul principio che la segmentazione, il riconoscimento, l'analisi grammaticale e semantica devono essere gestiti simultaneamente e allo stesso livello per produrre i migliori risultati.
Il sistema analizza le relazioni spaziali tra tutte le parti di un'equazione matematica secondo le regole stabilite nella sua grammatica specifica e specializzata, e poi usa quest'analisi per determinare la segmentazione. La grammatica stessa comprende un insieme di regole che descrivono come analizzare un'equazione e ogni regola è associata a una specifica relazione spaziale. Ad esempio, una regola di frazione definisce una relazione verticale tra un numeratore, una barra di frazione e un denominatore.
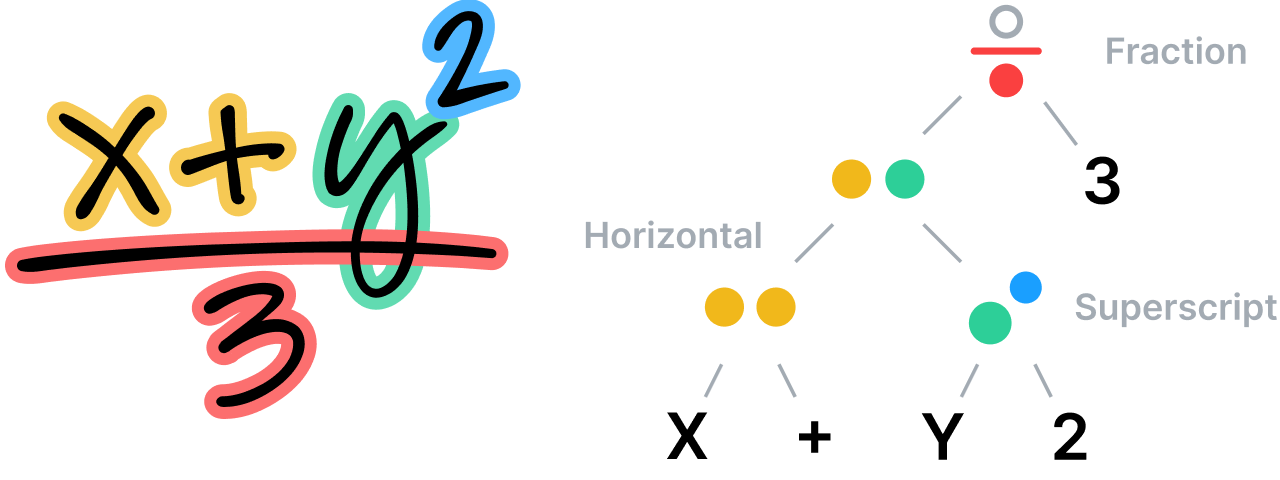
Comprendere le note non strutturate
Il riconoscimento preciso e immediato delle espressioni matematiche ha aperto nuove possibilità legate all'analisi del layout e del contenuto delle note scritte a mano.
Se il nostro motore di riconoscimento può interpretare correttamente le relazioni spaziali tra le parti di un'equazione matematica, potrebbe identificare con precisione anche altri tipi di contenuto non testuale? In questo caso, potremmo iniziare a superare i problemi posti dalle note non strutturate, usando la nostra tecnologia per identificare con precisione e persino abbellire elementi come i diagrammi disegnati a mano.
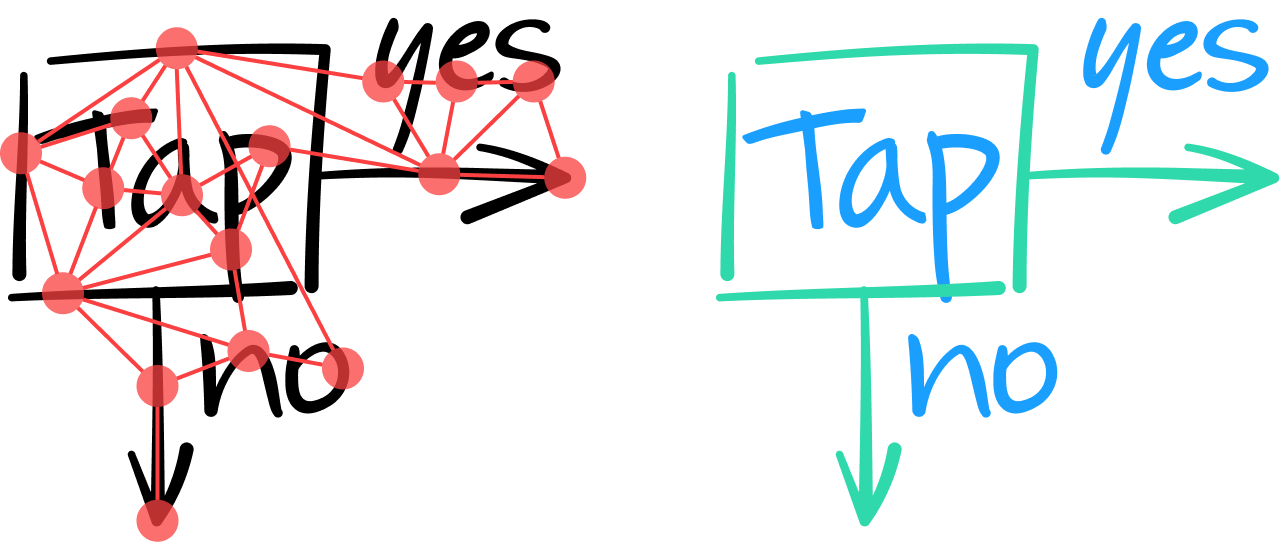
Abbiamo pensato che le architetture di reti neurali a grafo (GNN) fossero adatte allo scopo. L'idea di base consiste nel modellare un intero documento come un grafo, dove i tratti sono rappresentati da nodi e collegati da archi ai tratti vicini.
Analizzando in questo modo il contenuto di una nota, la GNN deve classificare tutti i tratti come testo o non testo. Per farlo, analizza le caratteristiche intrinseche di ogni tratto e, se necessario, prende in considerazione le informazioni contestuali fornite dagli archi e dai nodi vicini di un tratto.
Uno strato della GNN combina le caratteristiche di un nodo con quelle dei suoi vicini per produrre un vettore di valori numerici che rappresentano caratteristiche di livello superiore. Come con le reti neurali convoluzionali, si possono sovrapporre più strati per estrarre un maggior numero di caratteristiche globali, permettendo di prendere una decisione più fondata in merito al fatto che un tratto sia testo o meno. Ad esempio, nel seguente diagramma, le due linee verticali più a sinistra sono simili; solo integrando le informazioni contestuali dai tratti vicini, la GNN può classificare (nello strato di uscita) che il tratto più a sinistra fa parte di una figura geometrica quadrata, mentre quello accanto fa parte del carattere "T".
Deep learning e modello encoder-decoder
Non sempre è sufficiente offrire i due migliori sistemi di riconoscimento del testo e delle operazioni matematiche, soprattutto per gli utenti che lavorano o studiano in ambito scientifico. Questi utenti hanno spesso bisogno di inserire calcoli a metà del testo (e non in uno spazio separato nella pagina) e si aspettano che il motore di riconoscimento interpreti entrambi correttamente.
La sfida, quindi, era quella di progettare un sistema capace di riconoscere caratteri e parole combinati con espressioni matematiche, ovvero di analizzare un mix tra un linguaggio naturale unidimensionale (testo) e un linguaggio bidimensionale (matematica).
Con l'ondata del Deep Learning, sono emerse nuove architetture di reti neurali. Una di queste, l'encoder-decoder, è diventata molto popolare per risolvere i problemi di conversione sequence-to-sequence. Può gestire input e output di lunghezza variabile ed è diventata un riferimento in aree vicine al riconoscimento della scrittura, come il riconoscimento vocale. Il vantaggio chiave di un sistema encoder-decoder è che l'intero modello è addestrato dall'inizio alla fine, piuttosto che addestrare ogni elemento separatamente. È possibile utilizzare diverse architetture, compresi gli strati delle reti neurali convoluzionali, gli strati delle reti neurali ricorrenti, le unità LSTM (Long Short-Term Memory) e gli strati di attenzione comunemente utilizzati nel modello Transformer, per citarne solo alcuni.
Nel nostro caso, l'input dell'encoder-decoder è una sequenza di coordinate che rappresentano la traiettoria dei tratti fatti a penna. L'output è una sequenza di caratteri riconosciuti sotto forma di simboli LaTeX (ad esempio x^2 invece di x², o (\frac{ }) invece di una frazione).
Il futuro della scrittura a mano con l'IA
L'evoluzione della tecnologia di riconoscimento della scrittura ha ancora molta strada da fare. Stiamo già lavorando per estendere le capacità della nostra IA in modo che possa risolvere problemi come l'identificazione automatica della lingua e le tabelle interattive scritte a mano.
Crediamo che i modelli di Deep Learning offrano un grande potenziale di sviluppo e possano permetterci di unificare il nostro approccio in campi di ricerca che prima non erano collegati, come l'elaborazione del linguaggio naturale e l'analisi del layout dei documenti. Insieme alla crescente ubiquità di dispositivi digitali touch, siamo convinti che l'IA ci permetterà di passare dal "riconoscere ciò che vediamo" al "riconoscere ciò che volevamo fare". La differenza può sembrare sottile sulla pagina, ma in realtà rappresenta un nuovo cambio di paradigma. E noi vogliamo contribuire alla sua realizzazione.
La nostra visione del futuro è un mondo in cui chiunque può creare qualsiasi tipo di contenuto su qualsiasi dispositivo con la stessa libertà che avrebbe usando la carta, ma senza rinunciare nemmeno a un po' della potenza e della flessibilità del digitale. Grazie alla potenza dell'IA, questa visione si avvicina ogni giorno di più alla realtà.
