KI, neuronale Netze und Handschrifterkennung
KI verändert unser Verständnis davon, wie Menschen schreiben, und treibt die Technologie der digitalen Handschrift zu neuen Höhenflügen
Die Bedeutung der künstlichen Intelligenz
KI ist die Abkürzung für „Künstliche Intelligenz“. Sie bezieht sich auf den Bereich der Informatik, der sich mit der Entwicklung intelligenter Maschinen befasst, die bestimmte Fähigkeiten des menschlichen Gehirns wie Lesen, Verstehen oder Analysieren reproduzieren und verbessern können.
KI bei MyScript
Unsere Kernsoftwareprodukte basieren auf proprietärer KI-Technologie. Wir setzen KI ein, um handschriftliche Inhalte in über 70 Sprachen zu interpretieren, die Struktur handschriftlicher Notizen zu analysieren, mathematische Gleichungen zu verstehen und sogar handgezeichnete Musiknotationen zu erkennen und zu konvertieren.
Hinter unserer Technologie stehen über 20 Jahre Forschung und Entwicklung. Um das präziseste Handschrifterkennungsmodul der Welt zu entwickeln, haben wir die Feinheiten der Sprachbildung erforscht (und tun dies auch weiterhin): wie Sätze aus Wörtern und Wörter aus Buchstaben gebildet werden, wie diakritische Zeichen über oder unter bestimmten Vokalen platziert werden und so weiter.
Bei MyScript arbeiten mehrere Forschergruppen zusammen, um ein erstklassiges System zu schaffen und weiterzuentwickeln, das in der Lage ist, eine bemerkenswerte Bandbreite an handschriftlichen Inhalten zu verstehen.
Forschung zur Texthandschrift
Unser Forschungsteam für Texthandschrift verwendet Techniken des maschinellen Lernens, um Probleme zu lösen, die als Sequenz-zu-Sequenz- (oder seq2seq-) Konvertierungsprobleme formuliert werden können, zum Beispiel bei der Konvertierung von handschriftlichem Text in seine einzelnen Zeichen.
Die Techniken müssen an verschiedene Alphabete und Konventionen angepasst werden, um beispielsweise Rechts-nach-links-Sprachen wie Arabisch oder Hebräisch, diakritische Vokale in indischen Schriften, chinesische Ideogramme, das koreanische Hangul-Alphabet oder vertikal aufeinander folgende japanische Hiragana-, Katakana- oder Kanji-Zeichen erkennen zu können.
Forschung zur 2D-Handschrift
Dieses Team entwickelt mathematische Modelle, die auf zweidimensionalen Parsern und/oder Grammatiken basieren. Sie befassen sich mit Problemen, die mit seq2seq-Ansätzen nicht gelöst werden können. Hierzu zählen beispielsweise wie die Erkennung von mathematischen Ausdrücken, Musiknotationen oder Diagrammen und Tabellen. Das Team verwendet graphbasierte Techniken, um die Erkennung zu ermöglichen, wobei die Echtzeitverarbeitung eine große Herausforderung darstellt.
Forschung zur Verarbeitung natürlicher Sprache
Unser Team für die Verarbeitung natürlicher Sprache (NLP, natural language processing) entwickelt Algorithmen, die Sprachen so natürlich wie ein Mensch verstehen können. Das Team verwendet Textkorpora mit Hunderten von Millionen von Wörtern, die aus öffentlich zugänglichen Dokumenten und Artikeln stammen. Daraus erstellen sie Sprachvokabulare, verfeinern Modelle zur Vorhersage des nächsten Buchstabens in einem Satz und entwerfen Systeme zur Erkennung und Korrektur von Rechtschreibfehlern.
Datenerfassung
Ein Großteil unserer Arbeit wird durch anonymisierte Beispieldaten ermöglicht, die uns von Benutzern aus aller Welt freiwillig zur Verfügung gestellt werden. Diese „Trainingsbeispiele“ (wie sie in der KI-Forschung genannt werden) werden stets mit größter Rücksicht auf den Datenschutz und die Sicherheit behandelt. Sie sind ein wertvolles Wirtschaftsgut für das Unternehmen, da sie uns helfen, unsere Technologie zu verfeinern und zu verbessern.

Handschrifterkennung: die Herausforderungen
Die Handschrifterkennung stellt aufgrund der enormen Variabilität von Handschriftstilen eine große technische Herausforderung dar. Faktoren wie das Alter der Schreibenden, ihre Händigkeit, ihre Herkunftsländer und sogar die Schreibunterlage können sich auf die Schrift auswirken – ganz zu schweigen von den Auswirkungen der verschiedenen Sprachen und Alphabete.
Zur Veranschaulichung der damit verbundenen Herausforderungen: Eine gute Handschrifterkennungssoftware sollte in der Lage sein, ein einzelnes chinesisches Zeichen von über 30.000 möglichen Ideogrammen zu unterscheiden. Sie muss auch in der Lage sein, bidirektionale Schrift zu erkennen und zu dekodieren, sodass sie auch dann noch funktioniert, wenn ein Autor, der eine von rechts nach links geschriebene Sprache wie Arabisch oder Hebräisch verwendet, mehrere von links nach rechts geschriebene Fremdwörter in seinen Inhalt einbaut.
Bei Schreibschrift ist es für die Software noch schwieriger, einzelne Buchstaben zu trennen und zu erkennen, während verzögerte Striche, z. B. diakritische Zeichen, noch mehr Anlass zur Verwirrung geben. Das unstrukturierte Layout solcher Notizen erschwert die automatisierte Inhaltsanalyse erheblich, ebenso wie die Einbeziehung anderer Inhaltstypen wie mathematische Ausdrücke, Diagramme und Tabellen.
Auch der Zeitfaktor spielt eine Rolle: Handschrifterkennungssoftware muss in Echtzeit arbeiten und die Eingaben des Benutzers während des Schreibens interpretieren. Wenn der Benutzer seine Inhalte während des Schreibens ändert, zum Beispiel, indem er ein Wort durchstreicht, um es zu löschen, ein Leerzeichen einfügt oder einen Absatz verschiebt, muss das Erkennungsmodul damit Schritt halten können.
Darüber hinaus muss die Handschrifterkennungstechnologie in der Lage sein, sowohl eingegebene Buchstaben als auch handschriftliche Striche zu analysieren, sodass ein Benutzer eingegebenen Text aus Webseiten oder anderen Apps importieren und dann bei Bedarf von Hand mit Anmerkungen versehen kann. Ein gutes Erkennungsmodul muss solche komplexen Interaktionen genau interpretieren und zwischen Bearbeitungsgesten, dem Hinzufügen von diakritischen Zeichen oder dem Schreiben neuer Buchstaben und Wörter unterscheiden können.
In neuronale Netze investieren
Vor über 20 Jahren, als die internationale Forschungsgemeinschaft für Handschrifterkennung ihre Bemühungen auf verdeckte Markowmodelle (HMM, hidden Markov models) und Stützvektormaschinen (SVM, support vector machines) konzentrierte, schlug MyScript einen anderen Weg ein.
Wir haben uns stattdessen auf neuronale Netze konzentriert.
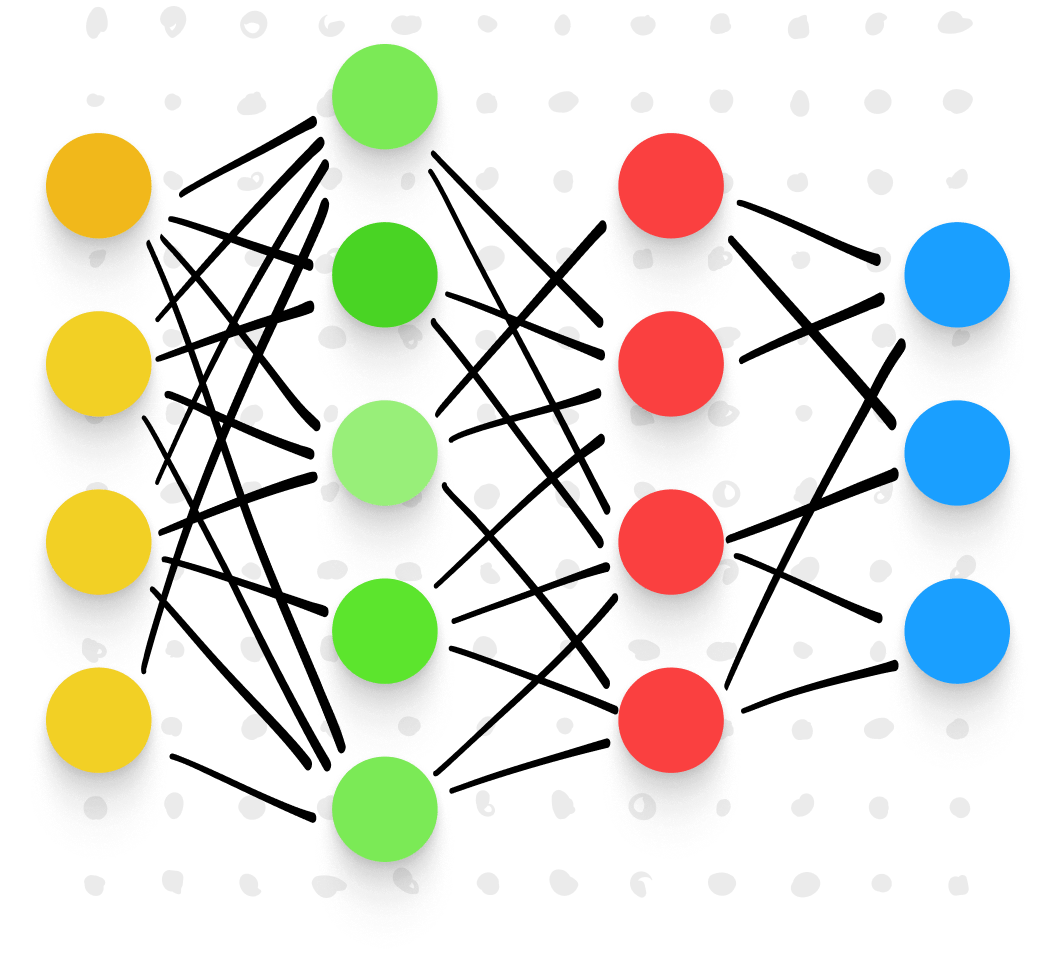
Ein neuronales Netz ist eine Art des maschinellen Lernens, das die Lernprozesse des menschlichen Gehirns nachahmt. Unterstützt von leistungsstarken Algorithmen erkennt ein neuronales Netz Muster in riesigen Datensätzen und ermöglicht so genauere Verallgemeinerungen über das, was untersucht wird, zum Beispiel Handschrift.
Neuronale Netze bestehen aus mathematischen Modellen, die so „trainiert“ sind, dass sie Muster anhand von vorgegebenen Variablen oder „Dimensionen“ erkennen. Sorgfältig programmierte Algorithmen teilen und sortieren die Daten immer wieder nach diesen Dimensionen. Sie klassifizieren und reklassifizieren, bis sich klare Muster ergeben.
Auf diese Weise können neuronale Netze Aufgaben ausführen, die für Menschen unmöglich wären. Sie sondieren riesige Datenmengen in kürzester Zeit und heben Muster hervor, die sonst möglicherweise unbemerkt blieben. Wir waren davon überzeugt, dass wir mit Hilfe neuronaler Netze das präziseste und fortschrittlichste Handschrifterkennungsmodul trainieren könnten, das die Welt je gesehen hat.
Neuronale Netze zur Handschrifterkennung nutzen
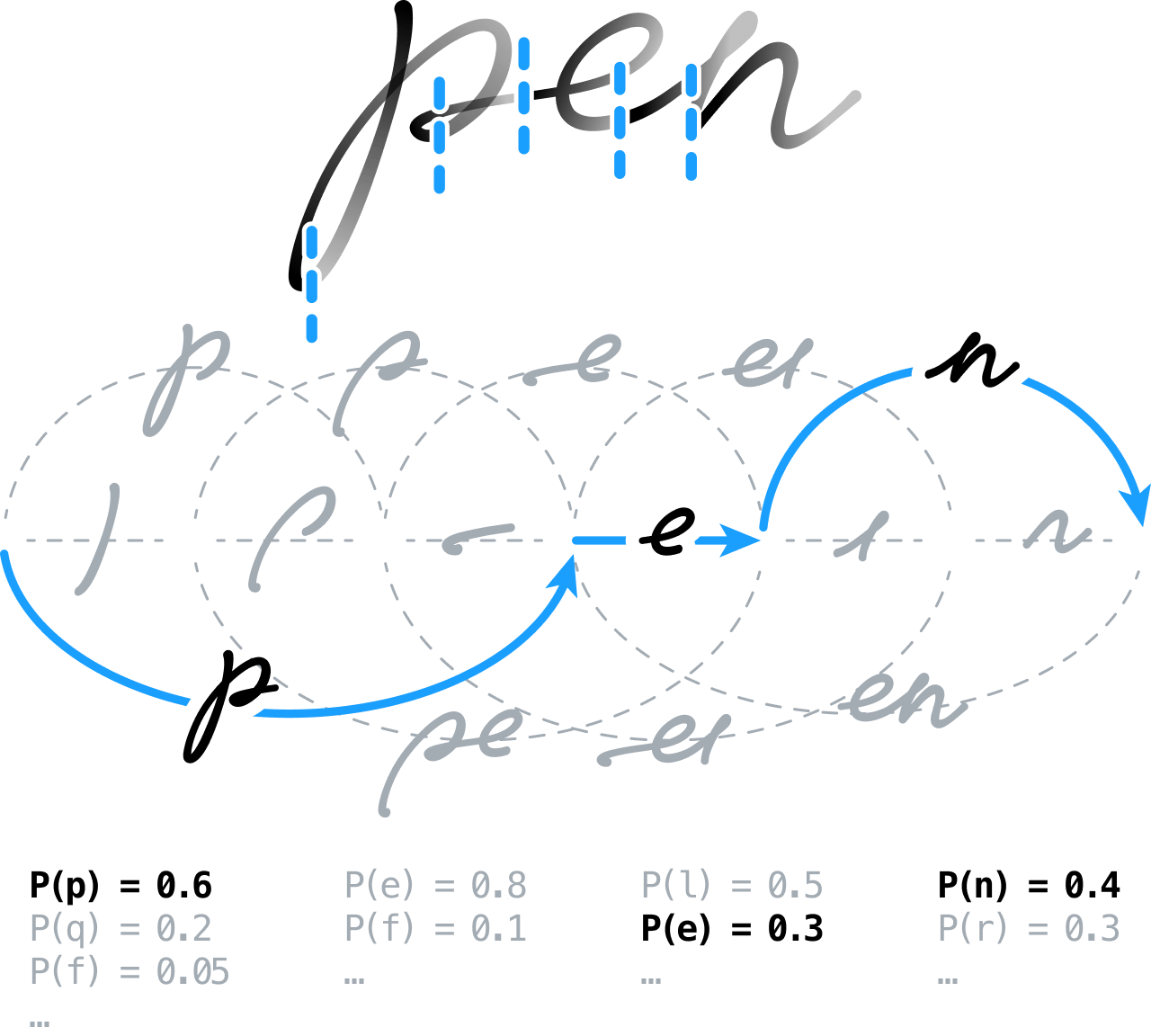
Von Anfang an war es unsere Idee, handschriftliche Inhalte durch Vorverarbeitung für die Analyse vorzubereiten. Hierzu sollten Aufgaben wie die Extraktion von Linien, die Normalisierung der Tinte und die Korrektur von Schrägstellungen durchgeführt werden. Wir würden dann das Signal übersegmentieren und das Erkennungsmodul später über die Position der Grenzen zwischen Buchstaben und Wörtern entscheiden lassen.
Dies bedeutete die Erstellung eines Segmentierungsgraphs durch Modellierung aller möglichen Segmentierungen, d. h. zusammenhängende Segmente wurden zu Zeichenhypothesen gruppiert, die dann mit Hilfe von neuronalen Feedforward-Netzen klassifiziert wurden. Wir haben einen neuartigen Ansatz verwendet, der auf einem allgemeinen Schema für diskriminatives Training basiert. Heutzutage wird diese Technik häufig im Rahmen der konnektionistischen zeitlichen Klassifikation (CTC, connectionist temporal classification) eingesetzt, um neuronale Sequenz-zu-Sequenz-Systeme zu trainieren.
Wir haben auch ein statistisches Sprachmodell nach dem neuesten Stand der Technik entwickelt und eingesetzt, das lexikalische, grammatikalische und semantische Informationen enthält, die zur Klärung und Lösung einiger der verbleibenden Mehrdeutigkeiten zwischen verschiedenen Zeichenkandidaten verwendet werden können.

KI für 2D-Sprachen trainieren
Unser Erfolg mit neuronalen Netzen hat uns in die Lage versetzt, das weltweit beste Handschrifterkennungsmodul für Druck- und Schreibschrift zu entwickeln. Einige Sprachen sind jedoch noch komplexer, was uns zur nächsten Herausforderung führte.
Erkennung chinesischer Zeichen
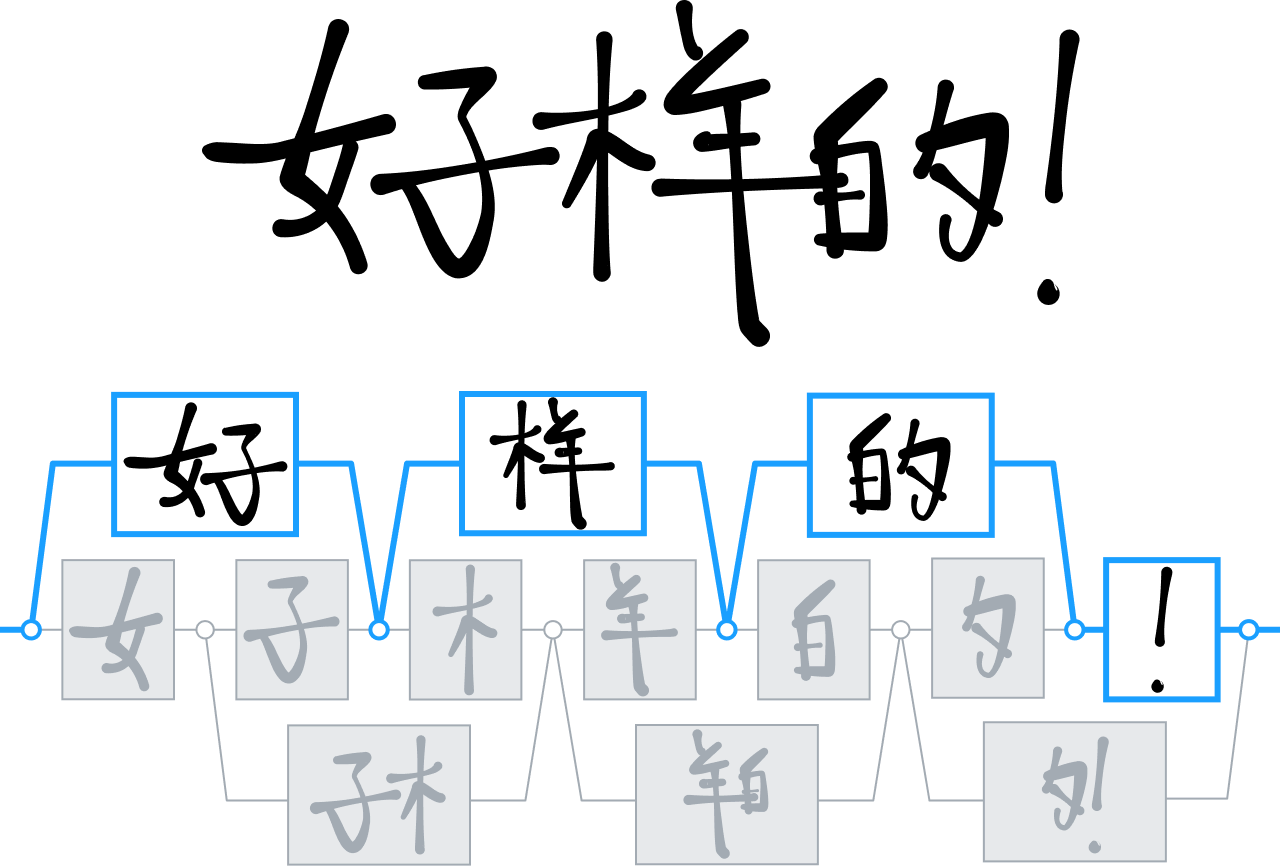
Im Laufe der Jahre hat MyScript eine Reihe von Technologien zur Analyse und Interpretation von visuellen und zweidimensionalen Sprachen entwickelt, insbesondere zur Erkennung chinesischer Ideogramme.
Während die meisten Konkurrenten in diesem Bereich Entscheidungsbaumtechniken zur Unterscheidung und Interpretation chinesischer Schriftzeichen verwendeten, setzten wir verstärkt auf neuronale Netze und trainierten unser Modul, um über 30.000 Ideogramme zu erkennen.
Es war das erste Mal, dass es einem Forschungsteam gelang, ein Netz dieser Größe erfolgreich zu trainieren. Dieser Erfolg wurde durch eine riesige Datenerfassungskampagne möglich, die zur größten Datenbank handschriftlicher chinesischer Zeichen führte, die je gesehen wurde.
Mit diesen Daten entwickelten wir eine neue neuronale Architektur, die speziell die Struktur chinesischer Schriftzeichen ausnutzt. Außerdem integrierten wir eine spezielle Clustering-Technik, um die Verarbeitungszeiten zu beschleunigen. Dank dieser Innovationen können wir ein neues Niveau der Handschrifterkennung in einem Markt anbieten, in dem die Eingabe über die Tastatur nach wie vor sehr mühsam und unflexibel ist. Sie ermöglichten es uns auch, das gleiche Maß an Unterstützung für andere Sprachen wie Japanisch, Hindi und Koreanisch hinzuzufügen.
Erkennung mathematischer Ausdrücke
Nachdem neuronale Netze erfolgreich zur Analyse und Erkennung einer Reihe von Weltsprachen eingesetzt wurden, kam ein neues Ziel in Sicht: die Erkennung mathematischer Ausdrücke.
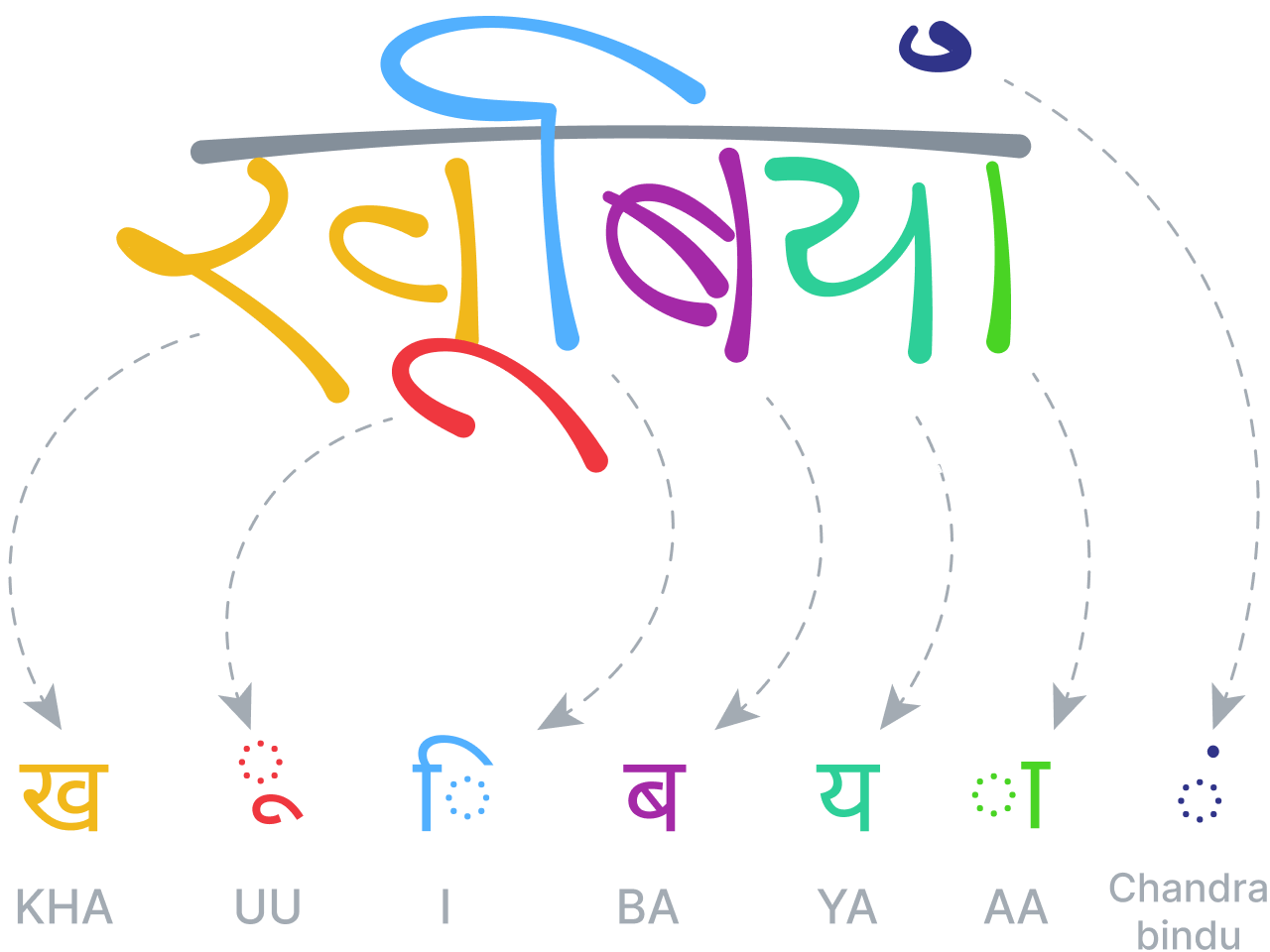
Während normale Sprachen strukturelle Sequenzen von Buchstaben und Wörtern aufweisen, lassen sich zweidimensionale oder visuelle Sprachen oft besser durch eine Baum- oder Graphenstruktur mit räumlichen Beziehungen zwischen den Knotenpunkten beschreiben. Wie beim Text beruht unser System zur Erkennung mathematischer Ausdrücke auf dem Prinzip, dass Segmentierung, Erkennung sowie grammatikalische und semantische Analyse gleichzeitig und auf derselben Ebene erfolgen müssen, um die besten Erkennungskandidaten zu erzeugen.
Das System analysiert die räumlichen Beziehungen zwischen allen Teilen einer mathematischen Gleichung nach den Regeln seiner spezifischen, spezialisierten Grammatik und verwendet diese Analyse dann zur Bestimmung der Segmentierung. Die Grammatik selbst besteht aus einem Satz von Regeln, die beschreiben, wie eine Gleichung zu analysieren ist, wobei jede Regel mit einer bestimmten räumlichen Beziehung verbunden ist. Eine Bruchregel definiert beispielsweise eine vertikale Beziehung zwischen Zähler, Bruchstrich und Nenner.
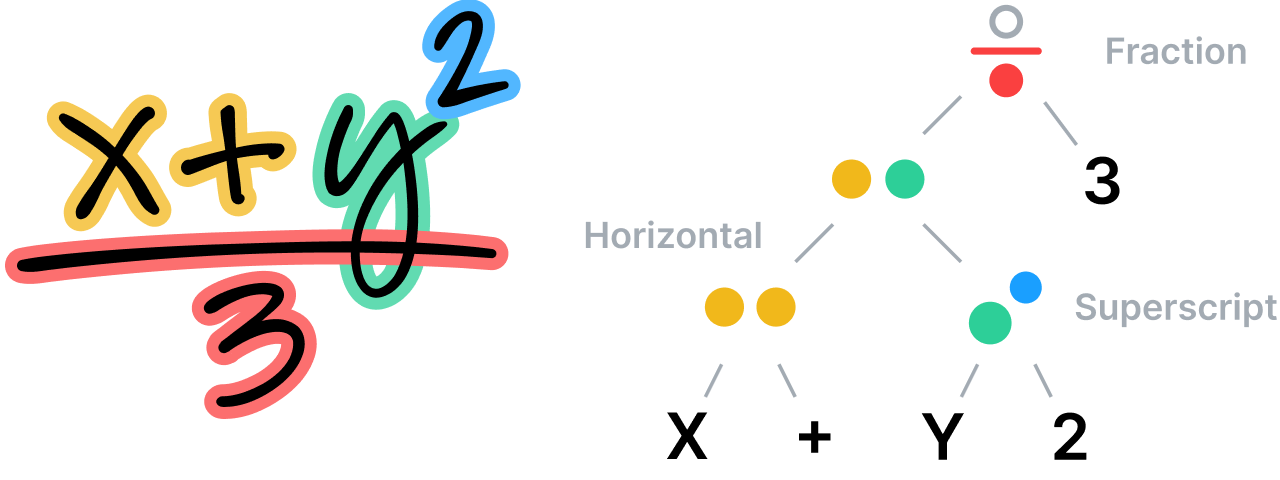
Unstrukturierte Notizen verstehen
Die genaue und sofortige Erkennung mathematischer Ausdrücke eröffnete neue Möglichkeiten in Bezug auf das Layout und den Inhalt handschriftlicher Notizen.
Wenn unser Erkennungsmodul die räumlichen Beziehungen zwischen Teilen von mathematischen Gleichungen korrekt interpretieren kann, könnte es dann auch Arten von Nicht-Text-Inhalten korrekt identifizieren? Wenn dies der Fall ist, könnten wir damit beginnen, die Probleme unstrukturierter Notizen zu überwinden, indem wir unsere Technologie nutzen, um Elemente wie handgezeichnete Diagramme genau zu identifizieren und sogar zu verschönern.
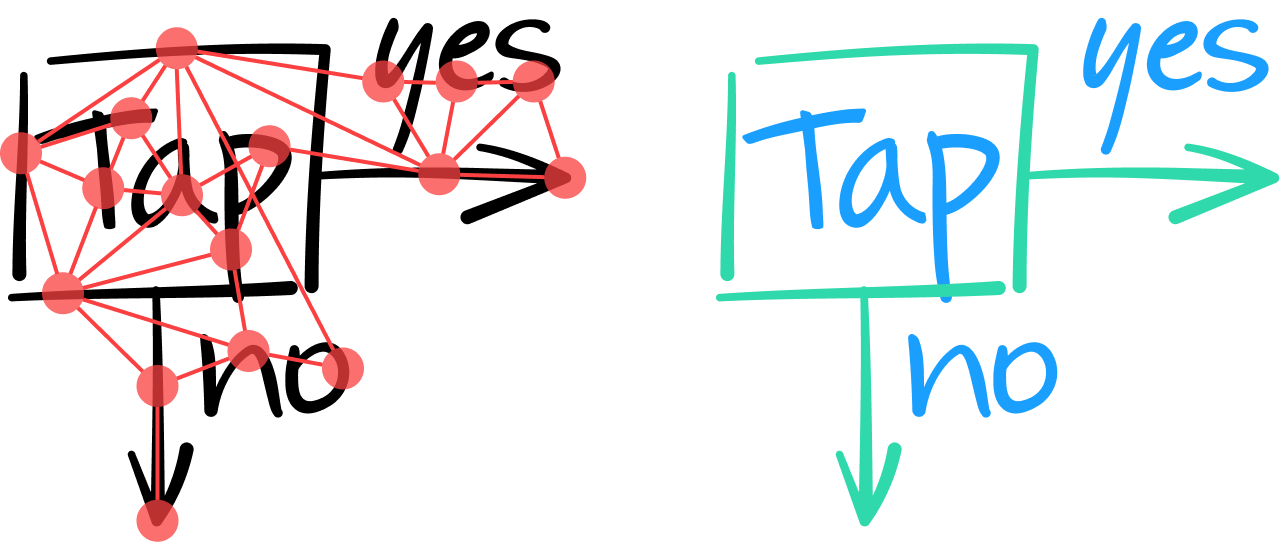
Wir waren der Meinung, dass Architekturen graphischer neuronaler Netze (GNN, graph neural network) für eine solche Aufgabe gut geeignet sind. Die Grundidee besteht darin, ein gesamtes Dokument als Graph zu modellieren, in dem die Striche durch Knoten dargestellt werden und durch Kanten mit ihren Nachbarstrichen verbunden sind.
Wenn die Inhalte einer Notiz auf diese Weise analysiert werden, muss das GNN alle Striche entweder als Text oder als Nicht-Text klassifizieren. Dies geschieht durch die Analyse der intrinsischen Merkmale jedes Strichs und, falls erforderlich, durch die Berücksichtigung der Kontextinformationen, die von den Nachbarkanten und -knoten eines Strichs geliefert werden.
Eine Schicht im GNN kombiniert die Merkmale eines Knotens mit denen seiner Nachbarn, um einen Vektor numerischer Werte zu erzeugen, die Merkmale auf einer höheren Schicht darstellen. Wie bei konvolutionären neuronalen Netzen (CNN, convolutional neural network) können mehrere Schichten übereinander gelegt werden, um eine zunehmende Anzahl umfassender Merkmale zu extrahieren. Hierdurch wird es möglich, eine fundiertere Entscheidung darüber zu treffen, ob es sich bei einem Strich um einen Textstrich handelt. Im folgenden Diagramm zum Beispiel sehen die beiden vertikalen Linien ganz links ähnlich aus. Erst durch die Einbeziehung von Kontextinformationen aus den benachbarten Strichen kann das GNN (auf der Ausgabeschicht) klassifizieren, dass der linke Strich Teil einer geometrischen quadratischen Form ist, während der daneben liegende Strich Teil des Buchstabens „T“ ist.
Deep Learning und das Encoder-Decoder-Modell
Es reicht nicht immer aus, zwei erstklassige Systeme für die Erkennung von Text und mathematischen Ausdrücken anzubieten, insbesondere für Benutzer, die in wissenschaftlichen Bereichen arbeiten oder studieren. Solche Benutzer müssen oft mathematische Ausdrücke als Teil des laufenden Textes schreiben, d. h. nicht in einem separaten Bereich auf der Seite. Außerdem erwarten sie, dass das Erkennungsmodul beides korrekt interpretiert.
Die Herausforderung bestand also in der Entwicklung eines Systems, das in der Lage ist, Buchstaben und Wörter gemischt mit mathematischen Ausdrücken zu erkennen, d. h. eine Kombination aus einer natürlichen eindimensionalen Sprache (Text) und einer zweidimensionalen Sprache (Mathematik) zu analysieren.
Mit der Deep-Learning-Welle erschienen neue Architekturen neuronaler Netze. Eine von ihnen, die Encoder-Decoder-Architektur, wurde sehr populär für die Lösung von Sequenz-zu-Sequenz-Konvertierungsproblemen. Sie kann Eingaben und Ausgaben variabler Länge verarbeiten und hat sich in Bereichen, die der Handschrifterkennung nahe stehen, wie der Spracherkennung, zum Stand der Technik entwickelt. Der Hauptvorteil eines Encoder-Decoder-Systems besteht darin, dass das gesamte Modell durchgängig trainiert wird, anstatt jedes Element einzeln zu trainieren. Es können verschiedene Architekturen eingesetzt werden, darunter Schichten konvolutionärer neuronaler Netze, Schichten rekurrenter neuronaler Netze, LSTM-Einheiten (long short-term memory; langes Kurzzeitgedächtnis) und aufmerksamkeitsbasierte Schichten, wie sie im Transformer-Modell verwendet werden.
In unserem Fall ist die Eingabe für den Encoder-Decoder eine Folge von Koordinaten, die den Verlauf handschriftlicher Stiftstriche darstellt. Die Ausgabe ist eine Folge erkannter Zeichen in Form von LaTeX-Symbolen (z. B. x^2 anstelle von x² oder (\frac{ }) anstelle eines Bruchs).


Zukunft der KI-Handschrift
Die Entwicklung der Technologie zur Handschrifterkennung ist noch lange nicht abgeschlossen. Wir arbeiten bereits daran, die Fähigkeiten unserer KI so zu erweitern, dass sie Probleme wie automatische Spracherkennung und interaktive handschriftliche Tabellen lösen kann.
Wir glauben, dass Deep-Learning-Modelle ein enormes Entwicklungspotenzial bieten und es uns ermöglichen können, unsere Herangehensweise an bisher nicht verwandte Forschungsbereiche wie die Verarbeitung natürlicher Sprache und die Analyse von Dokumentlayouts zu vereinheitlichen. In Verbindung mit der zunehmenden Verbreitung berührungsempfindlicher Digitalgeräte sind wir zuversichtlich, dass die KI es uns ermöglichen wird, von „erkennen, was wir sehen“ zu „erkennen, was beabsichtigt war“ überzugehen. Der Unterschied mag auf der Seite gering erscheinen, doch in Wirklichkeit handelt es sich um einen weiteren Paradigmenwechsel. Und wir sind entschlossen, dazu beizutragen, ihn zu erreichen.
Unsere Vision ist eine Welt, in der jeder jeden Inhaltstyp auf dem gewählten Gerät so frei erstellen kann wie auf Papier, ohne auf die volle Leistungsfähigkeit und Flexibilität der digitalen Technik verzichten zu müssen. Dank der Leistung der KI rückt diese Vision jeden Tag näher an die Realität heran.
