AI, neural networks and handwriting recognition
AI is transforming our understanding of how people write – and driving digital handwriting tech to new heights
The importance of AI
AI is short for ‘artificial intelligence’. It refers to the field of computer science involved in the creation of intelligent machines that can reproduce and enhance certain capabilities of the human brain – such as reading, understanding or analysis.
AI at MyScript
Our core software products are powered by proprietary AI technology . We use AI to interpret handwritten content in over 70 languages, to analyze the structure of handwritten notes, to understand mathematical equations and even to recognize and convert hand-drawn musical notation.
Our tech is backed by over 20 years of research and development. To build the world’s most accurate handwriting recognition engine, we’ve conducted (and continue to conduct) ongoing research into the minutiae of language formation: how sentences are constructed from words and words from characters; how diacritic marks are placed above or below certain vowels, and so on.
At MyScript, several groups of researchers collaborate to create and evolve a best-in-class system that’s capable of understanding a remarkable range of handwritten content.
Text handwriting research
Our Text Handwriting Research team uses machine learning techniques to solve problems that can be formulated as sequence-to-sequence (or seq2seq) conversion problems – such as when converting handwritten text into its constituent characters.
The techniques must be adapted to different alphabets and conventions, to enable the recognition of, for example, right-to-left languages like Arabic or Hebrew, diacritic vowels in Indian scripts, Chinese ideograms, the Korean Hangul alphabet or vertically sequenced Japanese Hiragana, Katakana or Kanji characters.
2D handwriting research
This team builds mathematical models based on bidimensional parsers and/or grammars. They address problems that can’t be solved by seq2seq approaches, like the recognition of mathematical expressions, musical notation or diagrams and charts. They employ graph-based techniques to enable recognition, with real-time processing a major challenge.
Natural language processing research
Our Natural Language Processing (NLP) team develops algorithms that can understand languages as naturally as any human being. The team uses textual corpora containing hundreds of millions of words obtained from publicly available documents and articles. From them, they build language vocabularies, elaborate models to predict the next character in a sentence, and design systems identifying and correcting misspellings.
Data collection
Much of our work is made possible by anonymized sample data shared with us voluntarily by users from around the world. These ‘training samples’ (as they’re known in AI research) are always treated with the greatest regard for privacy and security – and are a huge asset to the company, helping us to refine and enhance our technology.

Handwriting recognition: the challenges
Handwriting recognition poses significant technical challenges due to the huge variability of handwriting styles. Factors such as the age of the writer, their handedness, their country of origin and even the writing surface can impact the writing they produce – and that’s before considering the effects of different languages and alphabets.
To illustrate the challenges involved: good handwriting recognition software should be able to distinguish a single Chinese character from over 30,000 possible ideograms. It must also be able to recognize and decode bi-directional writing – so that it can continue to operate when a writer using a right-to-left language (like Arabic or Hebrew) includes a number of left-to-right foreign words in their content.
Cursive handwriting makes it even harder for software to segment and recognize individual characters, while delayed strokes (like diacritic marks) offer more opportunity for confusion. The unstructured layouts common to such notes make automated content analysis far trickier – as does the inclusion of other types of content, such as mathematical expressions, charts and tables.
Time is also a factor: handwriting recognition software must operate in real-time, interpreting the user’s inputs as they write. If the user edits their content while writing – for example, by scratching out a word to erase it, inserting a space or moving a paragraph – the recognition engine must be able to keep up.
In addition, handwriting recognition tech must be able to analyze typeset characters as well as handwritten strokes, so that a user can import typed text from web pages or other apps, then annotate it by hand where required. A good recognition engine must interpret such complex interactions accurately, differentiating between editing gestures, the addition of diacritic marks or the writing of new characters and words.
Investing in neural networks
Over 20 years ago, when the global handwriting recognition research community was focusing its efforts on Hidden Markov Models (HMM) and Support Vector Machines (SVM), MyScript took a different path.
We chose instead to focus on neural networks.
A neural network is a type of machine learning that mimics the learning processes of the human brain. Driven by powerful algorithms, a neural network identifies patterns in vast data sets, enabling more accurate generalizations about whatever we're studying – such as handwriting.
Neural networks are constructed from mathematical models ‘trained’ to identify patterns according to predetermined variables, or ‘dimensions’. Carefully programmed algorithms repeatedly split and sort the data according to these dimensions, classifying and reclassifying until clear patterns emerge.
In this way, neural networks can perform tasks that would be impossible for humans. They sift through huge quantities of data at speed, highlighting patterns that may otherwise escape attention. It was our belief that we could use neural networks to train the most accurate and advanced handwriting recognition engine the world had ever seen.
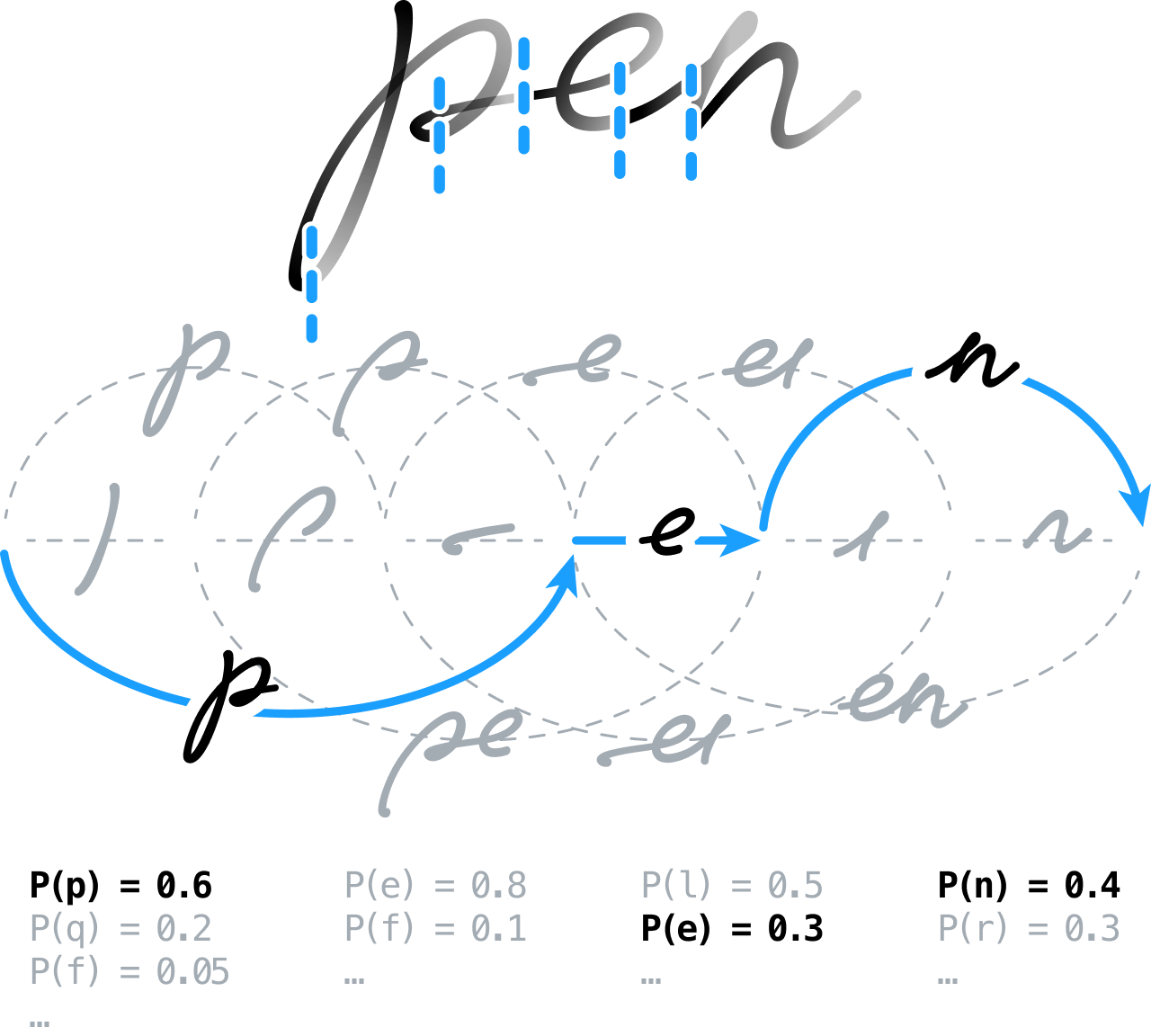
Using neural networks to recognize handwriting
From the outset, our idea was to preprocess handwritten content to ready it for analysis, performing such tasks as extracting lines, normalizing the ink and correcting any slant. We would then over-segment the signal and let the recognition engine decide the position of the boundaries between characters and words later.
This meant building a segmentation graph by modelling all possible segmentations – effectively, grouping contiguous segments into character hypotheses which were then classified by means of feedforward neural networks. We used a novel approach based on a global discriminative training scheme. Nowadays, this technique is quite commonly employed in the Connectionist Temporal Classification (CTC) framework, to train sequence-to-sequence neural systems.
We also built and employed a state-of-the-art statistical language model incorporating lexical, grammatical and semantic information that could be used to clarify and solve some of the remaining ambiguities between different character candidates.
Training AI for 2D languages
Our success with neural networks had enabled us to build the world’s best handwriting recognition engine for both printed and cursive scripts. But some languages offer even greater complexity – which led to our next challenge.
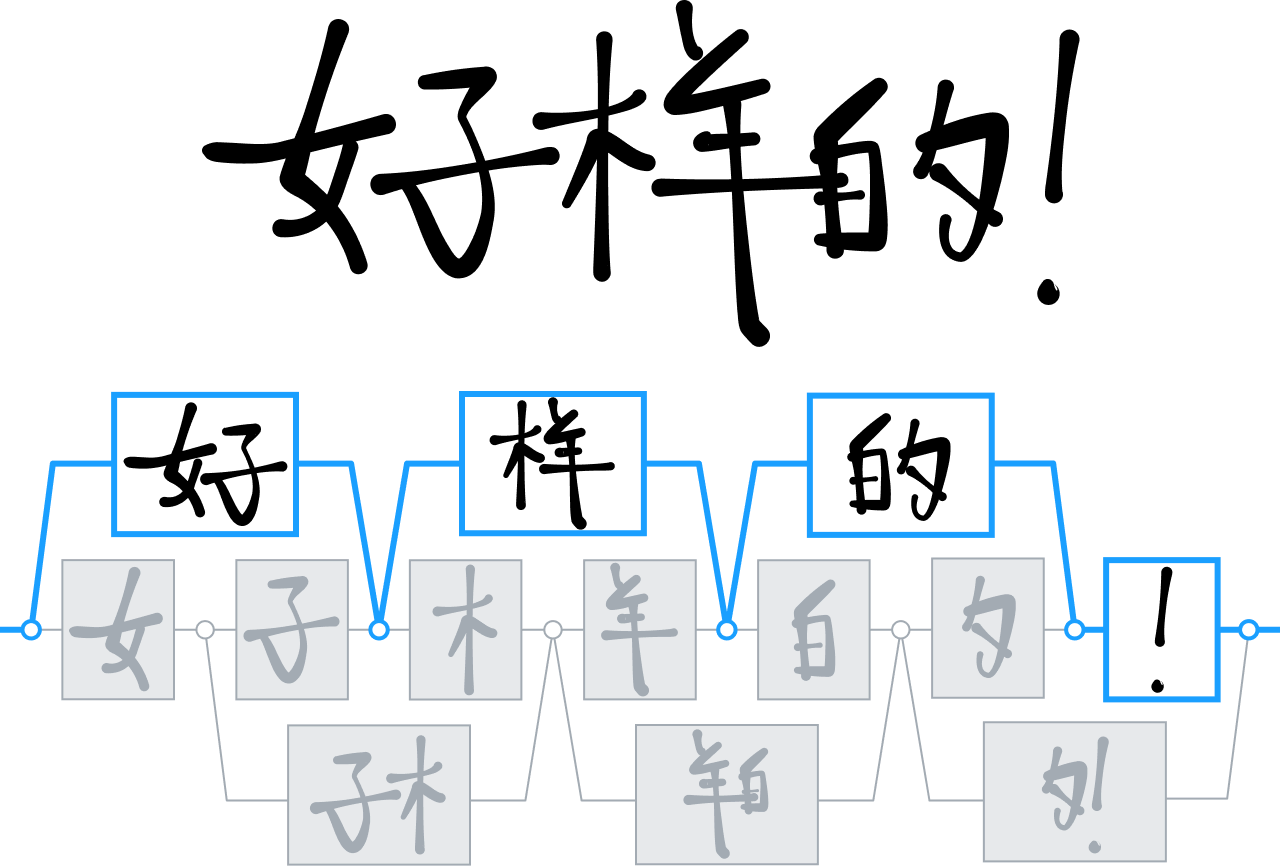
Chinese character recognition
Across the years, MyScript has developed a range of technologies to analyze and interpret two-dimensional languages – not least Chinese ideograms.
While most competitors in the field were using decision-tree techniques to differentiate and interpret Chinese characters, we doubled down on neural networks, training our engine to recognize over 30,000 ideograms.
It was the first time that a research team had successfully trained such a large network – something made possible by a huge data-collection campaign that resulted in the largest Chinese handwritten-character dataset ever seen.
We used this data to develop a new neural architecture that specifically exploits the structure of Chinese characters; we also integrated a specialized clustering technique to speed up processing times. These innovations enabled us to offer a new level of handwriting recognition to a market where keyboard entry remains painfully difficult and inflexible. They also enabled us to add the same level of support for other languages, such as Japanese, Hindi and Korean.
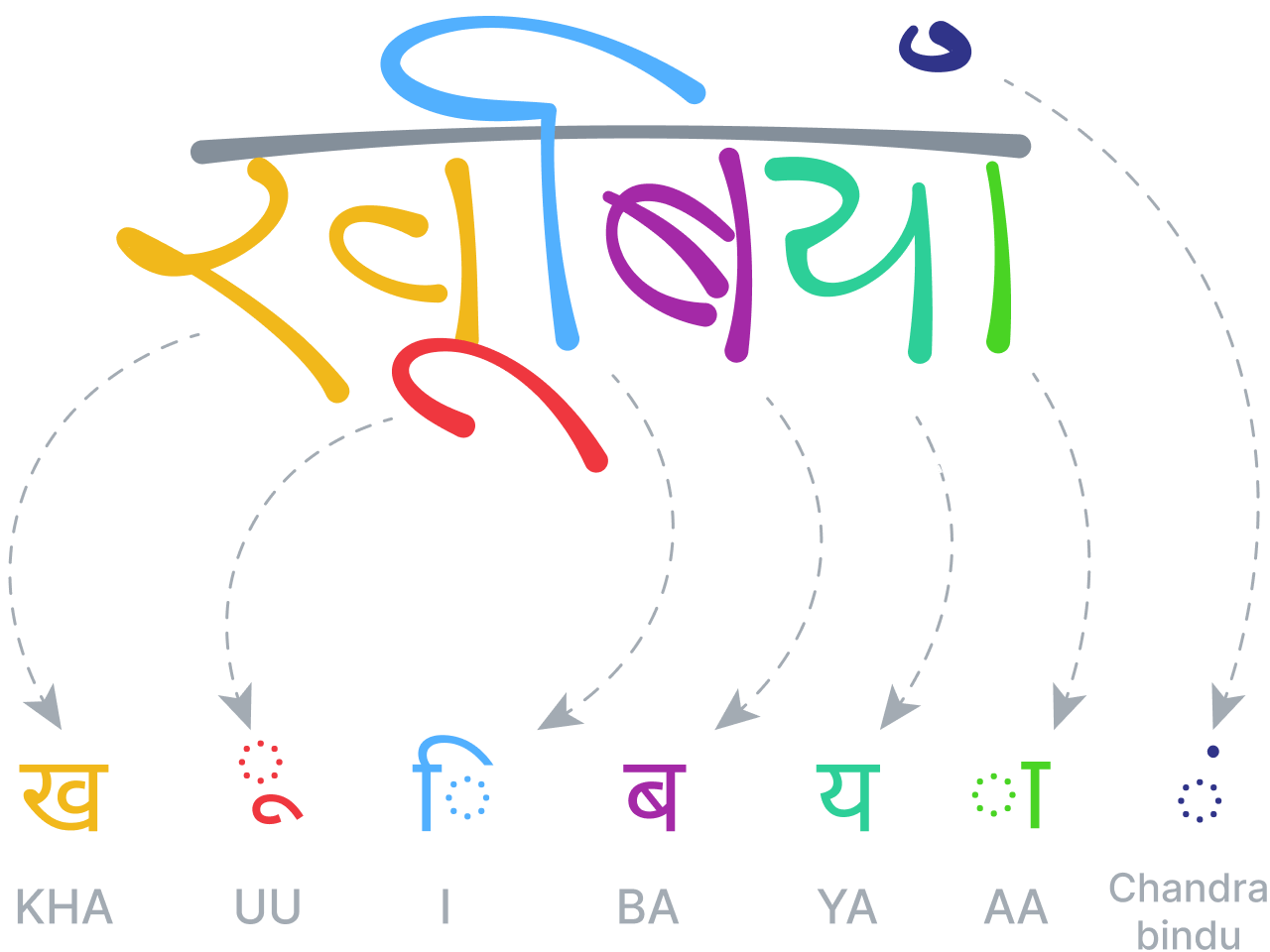
Math recognition
Having successfully employed neural networks to analyze and recognize a range of world languages, a new goal came into view: the recognition of mathematical expressions.
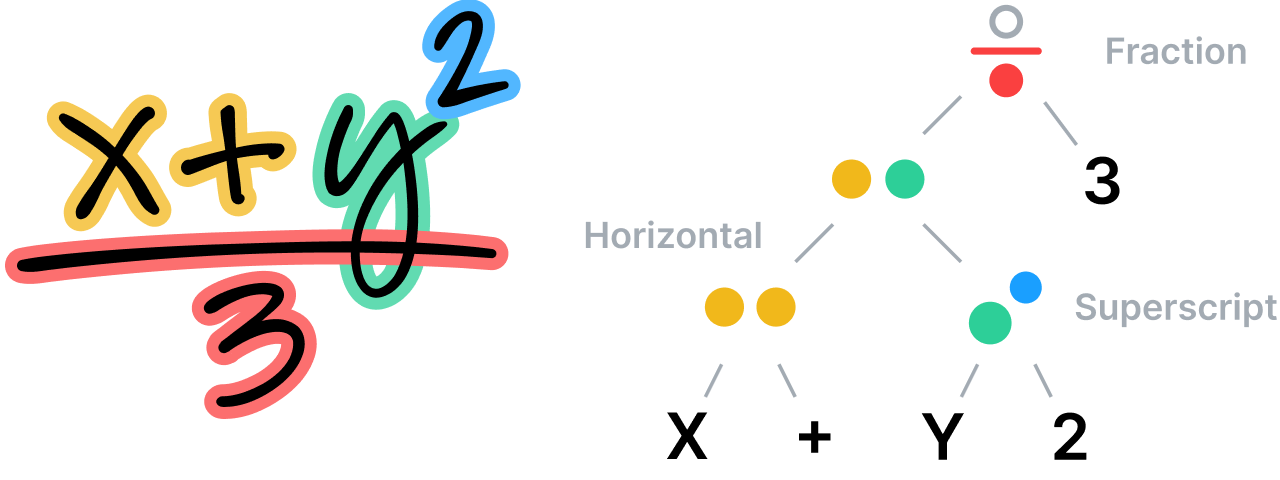
Where regular languages possess structural sequences of characters and words, two-dimensional (or visual) languages are often better described by a tree or graph structure, with spatial relationships between nodes. As with text, our math recognition system is built on the principle that segmentation, recognition, grammatical and semantic analysis must be handled concurrently and at the same level, so as to produce the best recognition candidates.
The system analyzes the spatial relationships between all parts of a mathematical equation in accordance with the rules laid down in its specific, specialized grammar, then uses this analysis to determine segmentation. The grammar itself comprises a set of rules describing how to parse an equation, where each rule is associated with a specific spatial relationship. For instance, a fraction rule defines a vertical relationship between a numerator, a fraction bar and a denominator.
Understanding unstructured notes
The accurate and immediate recognition of mathematical expressions opened new possibilities connected to the layout and content of handwritten notes.
If our recognition engine could correctly interpret the spatial relationships between parts of mathematical equations, could it also accurately identify types of non-text content? If so, we could begin to surmount the problems posed by unstructured notes, using our tech to accurately identify and even beautify elements such as hand-drawn diagrams.
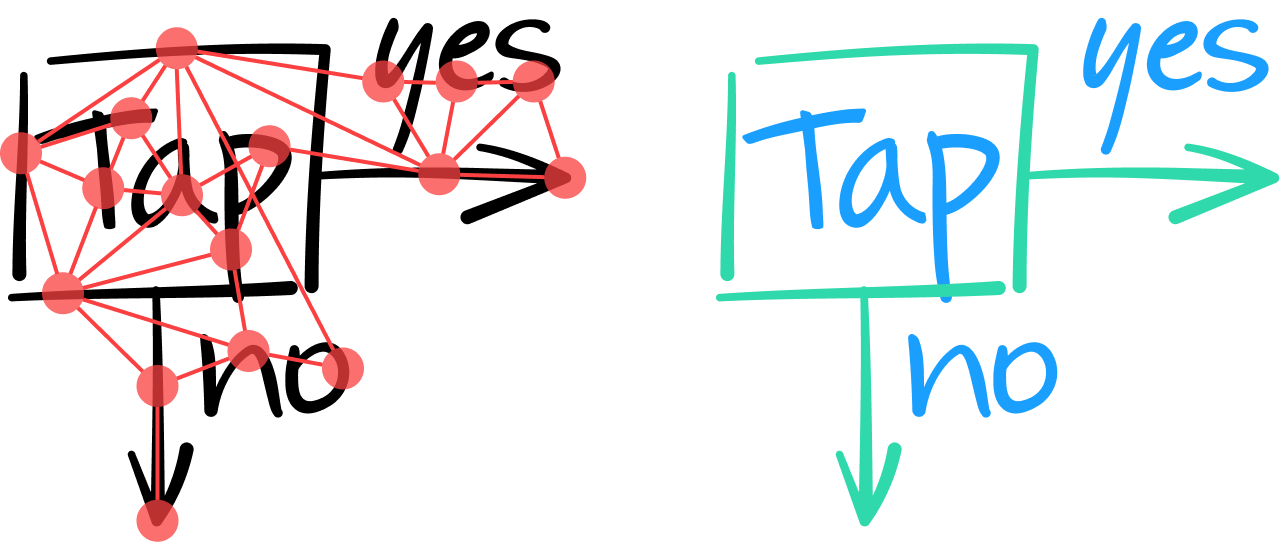
We believed that graph-based neural network (GNN) architectures were well-suited to such a task. The basic idea is to model an entire document as a graph, where strokes are represented by nodes and are connected by edges to their neighbor strokes.
When analyzing the content of a note in this way, the GNN must classify all strokes as either text or non-text. This is accomplished by analyzing the intrinsic features of each stroke and, where necessary, considering the contextual information provided by a stroke’s neighbor edges and nodes.
One layer in the GNN combines the features of a node with those of its neighbors to produce a vector of numerical values representing higher-level features. As with convolutional neural networks, several layers can be stacked to extract increasing numbers of global features – thereby enabling a more informed decision about whether a stroke constitutes a text stroke. For example, in the following diagram, the two leftmost vertical lines appear similar; it’s only by integrating contextual information from their neighbor strokes than the GNN can classify (at the output layer) that the leftmost stroke is part of a geometrical square shape, while the one beside it is part of the character ‘T’.
Deep learning and the encoder-decoder model
It’s not always enough to offer two best-in-class systems to recognize text and math – particularly for users working or studying in scientific fields. Such users often need to write inline math as part of running text (i.e. not in a separate space on the page) – and they expect the recognition engine to interpret both correctly.
The challenge, then, was to design a system that’s able to recognize characters and words mixed with mathematical expressions – i.e. of analyzing a combination of a natural unidimensional language (text) and a two-dimensional language (math).
With the Deep Learning wave, new neural network architectures appeared. One of them, the encoder-decoder, became very popular for solving sequence-to-sequence conversion problems. It can handle variable-length inputs and outputs, and has become state-of-the-art in fields close to handwriting recognition, such as speech recognition. The key advantage of an encoder-decoder system is that the entire model is trained end-to-end, as opposed to each element being trained separately. Several architectures can be employed, including convolutional neural network layers, recurrent neural network layers, long short-term memory units (LSTM) and attention-based layers commonly used in the Transformer model (to name just a few).
In our case, the input of the encoder-decoder is a sequence of coordinates representing the trajectory of handwritten pen strokes. The output is a sequence of recognized characters in the form of LaTeX symbols (for example, x^2 in place of x² or (\frac{ }) in place of a fraction).


The future of AI handwriting
The evolution of handwriting recognition tech is far from over. We're already working to extend the capabilities of our AI so that it can solve problems including automatic language identification and interactive handwritten tables.
We believe that Deep Learning models offer huge potential for development, and may enable us to unify our approach to previously unrelated fields of research – such as natural language processing and layout analysis. Combined with the increasing ubiquity of touch-enabled digital devices, we’re confident that AI will allow us to move from ‘recognizing what we see’ to ‘recognizing what was intended’. The difference may appear subtle on the page, but in reality this represents yet another paradigm shift. And we’re intent on helping to achieve it.
Our vision is of a world where anyone can create any type of content on their chosen device as freely as they might on paper, while retaining the full power and flexibility of digital. Thanks to the power of AI, that vision grows closer to reality every day.
